
Schematic diagram from the U-Net paper
By 苏剑林 | April 23, 2024
How to reduce the number of sampling steps while ensuring generation quality is a key issue in the application of diffusion models. Among early efforts, "Diffusion Model Discourse (4): DDIM = High-Perspective DDPM" introduced DDIM as the first attempt at accelerated sampling. Later, works introduced in "Diffusion Model Discourse (5): General Framework - SDE Edition" and "Diffusion Model Discourse (5): General Framework - ODE Edition" connected diffusion models with SDEs and ODEs. Consequently, corresponding numerical integration techniques were directly applied to accelerate diffusion model sampling. Among these, the relatively simple ODE acceleration techniques are the most abundant, an example of which we introduced in "Diffusion Model Discourse (21): Accelerating ODE Sampling with the Mean Value Theorem".
In this article, we introduce another particularly simple and effective acceleration trick—Skip Tuning, from the paper "The Surprising Effectiveness of Skip-Tuning in Diffusion Sampling". To be precise, it is used in conjunction with existing acceleration techniques to further improve generation quality. This means that while maintaining the same generation quality, it can further compress the number of sampling steps, thereby achieving acceleration.
Everything starts with the U-Net, which is the mainstream architecture for current diffusion models. The later U-ViT also maintains roughly the same form, simply replacing CNN-based ResBlocks with Attention-based ones.
U-Net originated from the paper "U-Net: Convolutional Networks for Biomedical Image Segmentation", originally designed for image segmentation. Its characteristic is that the input and output sizes are consistent, which perfectly fits the modeling requirements of diffusion models, so it was naturally migrated into the field. Formally, U-Net is very similar to a conventional AutoEncoder, involving gradual downsampling followed by gradual upsampling. However, it adds extra Skip Connections to solve the information bottleneck of the AutoEncoder:
Schematic diagram from the U-Net paper
Different papers implementing U-Net may vary in details, but they all share the same Skip Connection structure. Broadly speaking, the output of the first layer (block) has a "shortcut" directly to the last layer, the output of the second layer has a "shortcut" to the second-to-last layer, and so on. These "shortcuts" are the Skip Connections. Without Skip Connections, due to the "barrel effect" (limiting factor), the model's information flow would be restricted by the feature map with the smallest resolution. For tasks that require complete information, such as reconstruction or denoising, this would result in blurry outcomes.
In addition to avoiding information bottlenecks, Skip Connections also play a role in linear regularization. Obviously, if layers near the output only use Skip Connections as input, it is equivalent to the subsequent layers being added for nothing, and the model becomes more like a shallow or even linear model. Therefore, the addition of Skip Connections encourages the model to prioritize using the simplest possible predictive logic (i.e., closer to linear) and only use more complex logic when necessary—this is one of the inductive biases.
Once you understand U-Net, Skip Tuning can be explained in just a few sentences. We know that the sampling of a diffusion model is a multi-step recursive process from $\boldsymbol{x}_T$ to $\boldsymbol{x}_0$, which constitutes a complex non-linear mapping from $\boldsymbol{x}_T$ to $\boldsymbol{x}_0$. For practical considerations, we always hope to reduce the number of sampling steps. Regardless of which specific acceleration technique is used, it inherently reduces the non-linear capability of the entire sampling mapping.
The idea of many algorithms, such as ReFlow, is to adjust the noise schedule so that the sampling process follows a path that is as "straight" as possible. This makes the sampling function itself as linear as possible, thereby reducing the quality degradation caused by acceleration techniques. Skip Tuning, conversely, thinks: Since acceleration techniques lose non-linear capability, can we compensate for it from somewhere else? The answer lies in the Skip Connections. As we just mentioned, their presence encourages the model to simplify its predictive logic. If the Skip Connection weight is higher, the model is closer to a simple linear or even identity model. Conversely, by reducing the weight of the Skip Connections, one can increase the model's non-linear capability.
Of course, this is just one way to increase the model's non-linear capability. There is no guarantee that the non-linearity it adds is exactly the non-linearity lost by sampling acceleration. However, the experimental results of Skip Tuning show a certain equivalence between the two! So, as the name suggests, by performing a certain amount of Tuning on the weights of the Skip Connections, one can further improve the sampling quality after acceleration, or reduce the number of sampling steps while maintaining quality. The method of tuning is simple: assuming there are $k+1$ Skip Connections, we multiply the Skip Connection closest to the input layer by $\rho_{\text{top}}$, and the Skip Connection furthest from the input layer by $\rho_{\text{bottom}}$. The rest change uniformly according to depth. In most cases, we set $\rho_{\text{top}}=1$, so there is basically only one parameter, $\rho_{\text{bottom}}$, that needs to be tuned.
The experimental results of Skip Tuning are quite impressive. Two tables are excerpted below; for more experimental results and images, you can read the original paper.
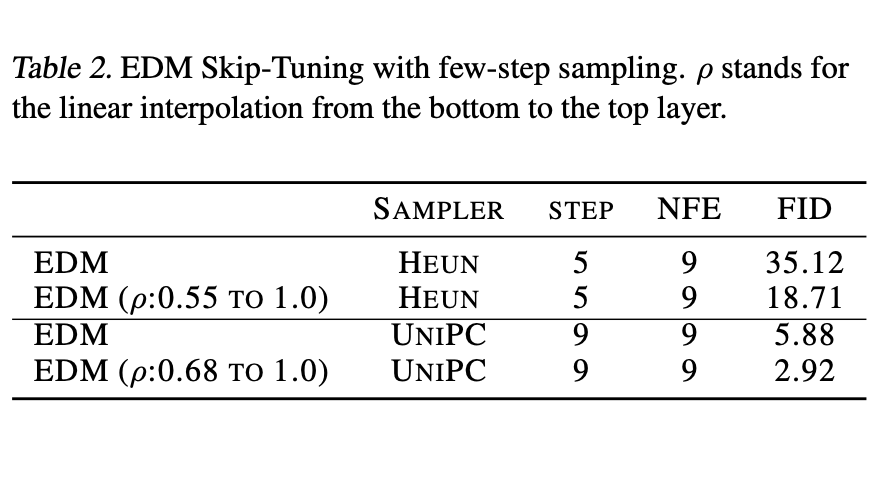
Skip Tuning Result 1
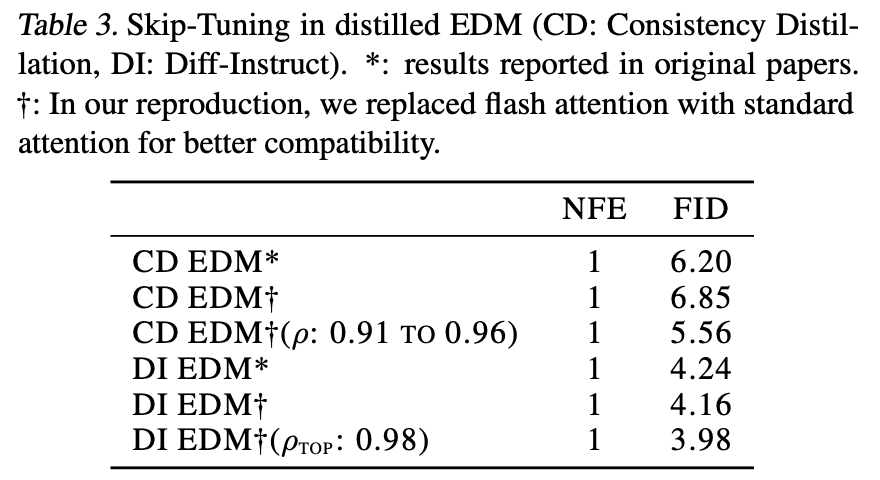
Skip Tuning Result 2
This is probably the simplest article in the diffusion series—no long-winded passages, no complex formulas. Readers could certainly understand Skip Tuning by reading the original paper directly, but I still wanted to introduce it. Like the previous article "Diffusion Model Discourse (23): SNR and Large Image Generation (Part 2)", it reflects the authors' unique imagination and power of observation, something I personally feel I lack quite a bit.
A paper relatively related to Skip Tuning is "FreeU: Free Lunch in Diffusion U-Net". it analyzes the roles of different components in the U-Net within diffusion models and finds that Skip Connections are mainly responsible for adding high-frequency details, while the backbone part is mainly responsible for denoising. In this way, we seem to be able to understand Skip Tuning from another perspective: Skip Tuning mainly experiments with ODE-based diffusion models. Such models often show increased noise when reducing sampling steps. Therefore, shrinking the Skip Connections relatively increases the weight of the backbone, enhancing the denoising capability, which is a "targeted remedy." Conversely, if it is an SDE-based diffusion model, the reduction ratio of Skip Connections might need to be decreased, or one might even need to increase the Skip Connection weights, because such models often produce overly smooth results when reducing sampling steps.
Skip Tuning adjusts Skip Connections. Does this mean models like DiT, which lack Skip Connections, have no chance to apply this? Probably not. Although DiT doesn't have Skip Connections, it still has residuals. The design of identity branches is inherently a linear regularization inductive bias. So, if there are no Skip Connections, tuning the residuals might also yield gains.
This article introduced a technique that can effectively improve the generation quality of diffusion models after accelerated sampling—reducing the weight of the U-Net "shortcuts" (i.e., Skip Connections). The entire methodological framework is very simple, clear, and intuitive, making it well worth learning.