By 苏剑林 | March 24, 2025
In the article "A First Look at muP: Scaling Laws for Cross-Model Hyperparameter Transfer", we derived muP (Maximal Update Parametrization) based on the scale invariance of forward propagation, backpropagation, loss increment, and feature changes. For some readers, this process may still seem somewhat tedious, though it has already been significantly simplified compared to the original paper. It should be noted that we introduced muP relatively completely in a single article, whereas the original muP paper is actually the fifth in the author's Tensor Programs series!
However, the good news is that in subsequent research "A Spectral Condition for Feature Learning", the authors discovered a new way of understanding it (referred to below as the "Spectral Condition"). It is more intuitive and concise than the original derivation of muP or my own derivation, yet it yields richer results than muP. It can be considered a "higher-order" version of muP—a representative work that is both simple and sophisticated.
Preparation
As the name suggests, the Spectral Condition is related to the spectral norm. Its starting point is a fundamental inequality of the spectral norm:
\begin{equation}\Vert\boldsymbol{x}\boldsymbol{W}\Vert_2\leq \Vert\boldsymbol{x}\Vert_2 \Vert\boldsymbol{W}\Vert_2\label{neq:spec-2}\end{equation}
where $\boldsymbol{x}\in\mathbb{R}^{d_{in}}, \boldsymbol{W}\in\mathbb{R}^{d_{in}\times d_{out}}$. As for $\Vert\cdot\Vert_2$, we can call it the "$2$-norm." For $\boldsymbol{x}$ and $\boldsymbol{x}\boldsymbol{W}$, which are vectors, the $2$-norm is simply the vector magnitude. For the matrix $\boldsymbol{W}$, its $2$-norm is also called the spectral norm, which is defined as the smallest constant $C$ such that $\Vert\boldsymbol{x}\boldsymbol{W}\Vert_2\leq C\Vert\boldsymbol{x}\Vert_2$ holds for all $\boldsymbol{x}$. In other words, the above inequality is a direct consequence of the definition of the spectral norm and requires no additional proof.
For more on the spectral norm, you can also refer to blog posts like "Lipschitz Constraints in Deep Learning: Generalization and Generative Models" and "The Path to Low-Rank Approximation (II): SVD". We will not expand on it here. Matrices also have a simpler $F$-norm (Frobenius norm), which is a simple generalization of vector magnitude:
\begin{equation}\Vert \boldsymbol{W}\Vert_F = \sqrt{\sum_{i=1}^{d_{in}}\sum_{j=1}^{d_{out}}W_{i,j}^2}\end{equation}
From the perspective of singular values, the spectral norm equals the largest singular value, while the $F$-norm equals the square root of the sum of the squares of all singular values. Therefore, we always have:
\begin{equation}\frac{1}{\sqrt{\min(d_{in},d_{out})}}\Vert \boldsymbol{W}\Vert_F \leq \Vert \boldsymbol{W}\Vert_2 \leq \Vert \boldsymbol{W}\Vert_F\end{equation}
This inequality describes the equivalence of the spectral norm and the $F$-norm (here, equivalence refers to an inequality relationship, not exact equality). Thus, when we encounter problems that are difficult to analyze due to the complexity of the spectral norm, we can consider replacing it with the $F$-norm to obtain an approximate result.
Finally, let's define RMS (Root Mean Square), which is a variant of vector magnitude:
\begin{equation}\Vert\boldsymbol{x}\Vert_{RMS} = \sqrt{\frac{1}{d_{in}}\sum_{i=1}^{d_{in}} x_i^2} = \frac{1}{\sqrt{d_{in}}}\Vert \boldsymbol{x}\Vert_2 \end{equation}
If generalized to matrices, it becomes $\Vert\boldsymbol{W}\Vert_{RMS} = \Vert \boldsymbol{W}\Vert_F/\sqrt{d_{in} d_{out}}$. The name is easy to understand: while vector magnitude or matrix $F$-norm can be called "Root Sum Square," RMS replaces "Sum" with "Mean." it is primarily used as an indicator of the average scale of vector or matrix elements. Substituting RMS into inequality $\eqref{neq:spec-2}$, we get:
\begin{equation}\Vert\boldsymbol{x}\boldsymbol{W}\Vert_{RMS}\leq \sqrt{\frac{d_{in}}{d_{out}}}\Vert\boldsymbol{x}\Vert_{RMS} \Vert\boldsymbol{W}\Vert_2\label{neq:spec-rms}\end{equation}
Desired Properties
Our previous approach to deriving muP involved a careful analysis of the forms of forward propagation, backpropagation, loss increment, and feature change, achieving scale invariance by adjusting initialization and learning rates. After "distilling" these, the Spectral Condition found that only forward propagation and feature change are necessary.
Simply put, the Spectral Condition expects the output and increment of each layer to have scale invariance. How should we understand this? If we denote each layer briefly as $\boldsymbol{x}_k= f(\boldsymbol{x}_{k-1}; \boldsymbol{W}_k)$, this can be translated to the expectation that both $\Vert\boldsymbol{x}_k\Vert_{RMS}$ and $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}$ are $\mathcal{O}(1)$:
1. $\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ is easy to understand; it represents the stability of forward propagation, which was also a requirement in the derivation of the previous article.
2. $\Delta\boldsymbol{x}_k$ represents the change in $\boldsymbol{x}_k$ caused by parameter changes, so $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ integrates the requirements for backpropagation and feature changes.
Some readers might wonder: shouldn't there at least be a requirement for "loss increment"? Not necessarily. In fact, we can prove that if $\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ and $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ hold for every layer, then $\Delta\mathcal{L}$ is automatically $\mathcal{O}(1)$. This is the first beautiful aspect of the Spectral Condition ideology: it reduces the four conditions originally needed for muP to two, shortening the analysis steps.
The proof is not difficult. The key here is that we assume $\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ and $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ hold for every layer, so they naturally hold for the last layer. Suppose the model has $K$ layers in total, and the loss function for a single sample is $\ell$, which is a function of $\boldsymbol{x}_K$, i.e., $\ell(\boldsymbol{x}_K)$. For simplicity, the label input is omitted here as it is not a variable for the following analysis.
According to the assumption, $\Vert\boldsymbol{x}_K\Vert_{RMS}$ is $\mathcal{O}(1)$, so $\ell(\boldsymbol{x}_K)$ is naturally $\mathcal{O}(1)$. Furthermore, because $\Vert\Delta\boldsymbol{x}_K\Vert_{RMS}$ is $\mathcal{O}(1)$, then $\Vert\boldsymbol{x}_K + \Delta\boldsymbol{x}_K\Vert_{RMS} \leq \Vert\boldsymbol{x}_K\Vert_{RMS} + \Vert\Delta\boldsymbol{x}_K\Vert_{RMS}$ is also $\mathcal{O}(1)$. Thus, $\ell(\boldsymbol{x}_K + \Delta\boldsymbol{x}_K)$ is $\mathcal{O}(1)$, and consequently:
\begin{equation}\Delta \ell = \ell(\boldsymbol{x}_K + \Delta\boldsymbol{x}_K) - \ell(\boldsymbol{x}_K) = \mathcal{O}(1)\end{equation}
Therefore, the loss increment for a single sample $\Delta \ell$ is $\mathcal{O}(1)$, and since $\Delta\mathcal{L}$ is the average of all $\Delta \ell$, it is also $\mathcal{O}(1)$. In this way, we have proven that $\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ and $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ automatically encompass $\Delta\mathcal{L}=\mathcal{O}(1)$. The principle, simply put, is that $\Delta\mathcal{L}$ is a function of the final layer output and its increment; if they are stabilized, $\Delta\mathcal{L}$ will naturally be stabilized.
The Spectral Condition
Next, let's see how to satisfy the two desired properties. Since neural networks are primarily based on matrix multiplication, we first consider the simplest linear layer $\boldsymbol{x}_k = \boldsymbol{x}_{k-1} \boldsymbol{W}_k$, where $\boldsymbol{W}_k\in\mathbb{R}^{d_{k-1}\times d_k}$. To satisfy the condition $\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$, the Spectral Condition does not assume i.i.d. distributions and calculate expectation/variance as in traditional initialization analysis. Instead, it directly applies inequality $\eqref{neq:spec-rms}$:
\begin{equation}\Vert\boldsymbol{x}_k\Vert_{RMS}\leq \sqrt{\frac{d_{k-1}}{d_k}}\Vert\boldsymbol{x}_{k-1}\Vert_{RMS}\, \Vert\boldsymbol{W}_k\Vert_2\end{equation}
Note that this inequality can potentially achieve equality and is, in a sense, the most precise bound. Therefore, if the input $\Vert\boldsymbol{x}_{k-1}\Vert_{RMS}$ is already $\mathcal{O}(1)$, then for the output $\Vert\boldsymbol{x}_k\Vert_{RMS}$ to be $\mathcal{O}(1)$, we must have:
\begin{equation}\sqrt{\frac{d_{k-1}}{d_k}}\Vert\boldsymbol{W}_k\Vert_2 = \mathcal{O}(1)\quad\Rightarrow\quad \Vert\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)\label{eq:spec-c1}\end{equation}
This proposes the first Spectral Condition—a requirement for the spectral norm of $\boldsymbol{W}_k$. It is independent of initialization and distribution assumptions and is purely the result of analysis and algebra. This is what I consider the second beautiful aspect of the Spectral Condition—it simplifies the analysis process. Of course, the basic contents of the spectral norm are omitted here; if they were included, the length might not necessarily be shorter than an analysis under distribution assumptions. However, distribution assumptions are ultimately more limited, whereas the algebraic framework here is more flexible.
After analyzing $\Vert\boldsymbol{x}_k\Vert_{RMS}$, we turn to $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}$. The source of the increment $\Delta\boldsymbol{x}_k$ consists of two parts: first, the parameters changing from $\boldsymbol{W}_k$ to $\boldsymbol{W}_k+\Delta \boldsymbol{W}_k$, and second, the input $\boldsymbol{x}_{k-1}$ changing from $\boldsymbol{x}_{k-1}$ to $\boldsymbol{x}_{k-1} + \Delta\boldsymbol{x}_{k-1}$ due to parameter changes in previous layers. Thus:
\begin{equation}\begin{aligned}
\Delta\boldsymbol{x}_k =&\, (\boldsymbol{x}_{k-1} + \Delta\boldsymbol{x}_{k-1})(\boldsymbol{W}_k+\Delta \boldsymbol{W}_k) - \boldsymbol{x}_{k-1}\boldsymbol{W}_k \\[5pt]
=&\, \boldsymbol{x}_{k-1} (\Delta \boldsymbol{W}_k) + (\Delta\boldsymbol{x}_{k-1})\boldsymbol{W}_k + (\Delta\boldsymbol{x}_{k-1})(\Delta \boldsymbol{W}_k)
\end{aligned}\end{equation}
Therefore:
\begin{equation}\begin{aligned}
\Vert\Delta\boldsymbol{x}_k\Vert_{RMS} =&\, \Vert\boldsymbol{x}_{k-1} (\Delta \boldsymbol{W}_k) + (\Delta\boldsymbol{x}_{k-1})\boldsymbol{W}_k + (\Delta\boldsymbol{x}_{k-1})(\Delta \boldsymbol{W}_k)\Vert_{RMS} \\[5pt]
\leq&\, \Vert\boldsymbol{x}_{k-1} (\Delta \boldsymbol{W}_k)\Vert_{RMS} + \Vert(\Delta\boldsymbol{x}_{k-1})\boldsymbol{W}_k\Vert_{RMS} + \Vert(\Delta\boldsymbol{x}_{k-1})(\Delta \boldsymbol{W}_k)\Vert_{RMS} \\[5pt]
\leq&\, \sqrt{\frac{d_{k-1}}{d_k}}\left({\begin{gathered}\Vert\boldsymbol{x}_{k-1}\Vert_{RMS}\,\Vert\Delta \boldsymbol{W}_k\Vert_2 + \Vert\Delta\boldsymbol{x}_{k-1}\Vert_{RMS}\,\Vert \boldsymbol{W}_k\Vert_2 \\[5pt]
+ \Vert\Delta\boldsymbol{x}_{k-1}\Vert_{RMS}\,\Vert\Delta \boldsymbol{W}_k\Vert_2\end{gathered}} \right)
\end{aligned}\end{equation}
Analyzing item by item:
\begin{equation}\underbrace{\Vert\boldsymbol{x}_{k-1}\Vert_{RMS}}_{\mathcal{O}(1)}\,\Vert\Delta \boldsymbol{W}_k\Vert_2 + \underbrace{\Vert\Delta\boldsymbol{x}_{k-1}\Vert_{RMS}}_{\mathcal{O}(1)}\,\underbrace{\Vert \boldsymbol{W}_k\Vert_2}_{\mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)} + \underbrace{\Vert\Delta\boldsymbol{x}_{k-1}\Vert_{RMS}}_{\mathcal{O}(1)}\,\Vert\Delta \boldsymbol{W}_k\Vert_2\end{equation}
From this, we see that for $\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)$ to hold, we need:
\begin{equation}\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)\label{eq:spec-c2}\end{equation}
This is the second Spectral Condition—a requirement for the spectral norm of $\Delta\boldsymbol{W}_k$.
The above analysis did not consider non-linearities. In fact, as long as the activation function is element-wise and its derivative can be bounded by a constant (which is true for common activation functions like ReLU, Sigmoid, and Tanh), the results remain consistent even when considering non-linear activations. This is what was mentioned in the previous article as "the influence of the activation function being scale-invariant." If readers are still concerned, they can derive it for themselves.
Spectral Normalization
Now that we have the two spectral conditions $\eqref{eq:spec-c1}$ and $\eqref{eq:spec-c2}$, we need to see how to design the model itself and the model optimization to satisfy these conditions.
Note that both $\boldsymbol{W}_k$ and $\Delta \boldsymbol{W}_k$ are matrices. The standard way to make a matrix satisfy a spectral norm condition is usually through Spectral Normalization (SN). First, we want the initialized $\boldsymbol{W}_k$ to satisfy $\Vert\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$. This can be achieved by choosing any initialization matrix $\boldsymbol{W}_k'$ and then applying spectral normalization:
\begin{equation}\boldsymbol{W}_k = \sigma\sqrt{\frac{d_k}{d_{k-1}}}\frac{\boldsymbol{W}_k'}{\Vert\boldsymbol{W}_k'\Vert_2}\end{equation}
where $\sigma > 0$ is a scale-invariant constant. Similarly, for any update $\boldsymbol{U}_k$ provided by an optimizer, we can reconstruct $\Delta \boldsymbol{W}_k$ via spectral normalization:
\begin{equation}\Delta \boldsymbol{W}_k = \eta\sqrt{\frac{d_k}{d_{k-1}}}\frac{\boldsymbol{U}_k}{\Vert\boldsymbol{U}_k\Vert_2}\end{equation}
where $\eta > 0$ is also a scale-invariant constant (learning rate). Thus, in every step, we have $\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$. Since the spectral norm of the initialization and every update satisfies $\mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$, $\Vert\boldsymbol{W}_k\Vert_2$ will satisfy $\mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$ from beginning to end, fulfilling both spectral conditions.
At this point, some readers might wonder: by only considering the stability of the initialization and increments, can we really guarantee the stability of $\boldsymbol{W}_k$? Isn't it possible for $\Vert\boldsymbol{W}_k\Vert_{RMS}\to\infty$? The answer is that it is possible. The term $\mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$ emphasizes the relationship with the model scale (currently mainly width). It doesn't rule out the possibility of training collapse due to improper settings of other hyperparameters; rather, it expresses that after setting it this way, even if collapse happens, the reason will not be due to scale changes.
Singular Value Clipping
To realize the spectral norm conditions, besides the standard method of spectral normalization, we can also consider Singular Value Clipping (SVC). This part is added by myself and did not appear in the original paper, but it can explain some interesting results.
From the perspective of singular values, spectral normalization scales the largest singular value to 1 and scales all other singular values simultaneously. Singular value clipping is in some ways more permissive; it only sets singular values greater than 1 to 1, while leaving singular values that are already less than or equal to 1 unchanged:
\begin{equation}\mathop{\text{SVC}}(\boldsymbol{W}) = \boldsymbol{U}\min(\boldsymbol{\Lambda},1)\boldsymbol{V}^{\top},\qquad \boldsymbol{U},\boldsymbol{\Lambda},\boldsymbol{V}^{\top} = \mathop{\text{SVD}}(\boldsymbol{W})\end{equation}
In contrast, spectral normalization is $\mathop{\text{SN}}(\boldsymbol{W})=\boldsymbol{U}(\boldsymbol{\Lambda}/\max(\boldsymbol{\Lambda}))\boldsymbol{V}^{\top}$. Replacing spectral normalization with singular value clipping, we get:
\begin{equation}\boldsymbol{W}_k = \sigma\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{SVC}}(\boldsymbol{W}_k'), \qquad \Delta \boldsymbol{W}_k = \eta\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{SVC}}(\boldsymbol{U}_k)\end{equation}
A drawback of singular value clipping is that it can only guarantee the clipped spectral norm equals 1 if at least one singular value is greater than or equal to 1. If this is not satisfied, we can consider multiplying by a factor $\lambda > 0$ before clipping, i.e., using $\mathop{\text{SVC}}(\lambda\boldsymbol{W})$. However, different scale factors yield different results, and it's not easy to determine a suitable one. Nevertheless, we can consider a limit version:
\begin{equation}\lim_{\lambda\to\infty} \mathop{\text{SVC}}(\lambda\boldsymbol{W}) = \mathop{\text{msign}}(\boldsymbol{W})\end{equation}
Here, $\mathop{\text{msign}}$ is the matrix-version sign function used in Muon (refer to "Appreciation of the Muon Optimizer: Essential Leap from Vectors to Matrices"). Replacing spectral normalization or singular value clipping with $\mathop{\text{msign}}$, we get:
\begin{equation}\Delta \boldsymbol{W}_k = \eta\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{msign}}(\boldsymbol{U}_k)\end{equation}
In this way, we essentially obtain a generalized Muon optimizer. The standard Muon applies $\mathop{\text{msign}}$ to momentum, whereas this allows us to apply $\mathop{\text{msign}}$ to any update provided by an existing optimizer. Coincidentally, some time ago, someone on Twitter experimented with applying $\mathop{\text{msign}}$ to Adam updates (calling it "Mudamw", link) and found that it performed slightly better than Muon, as shown in the figure below:
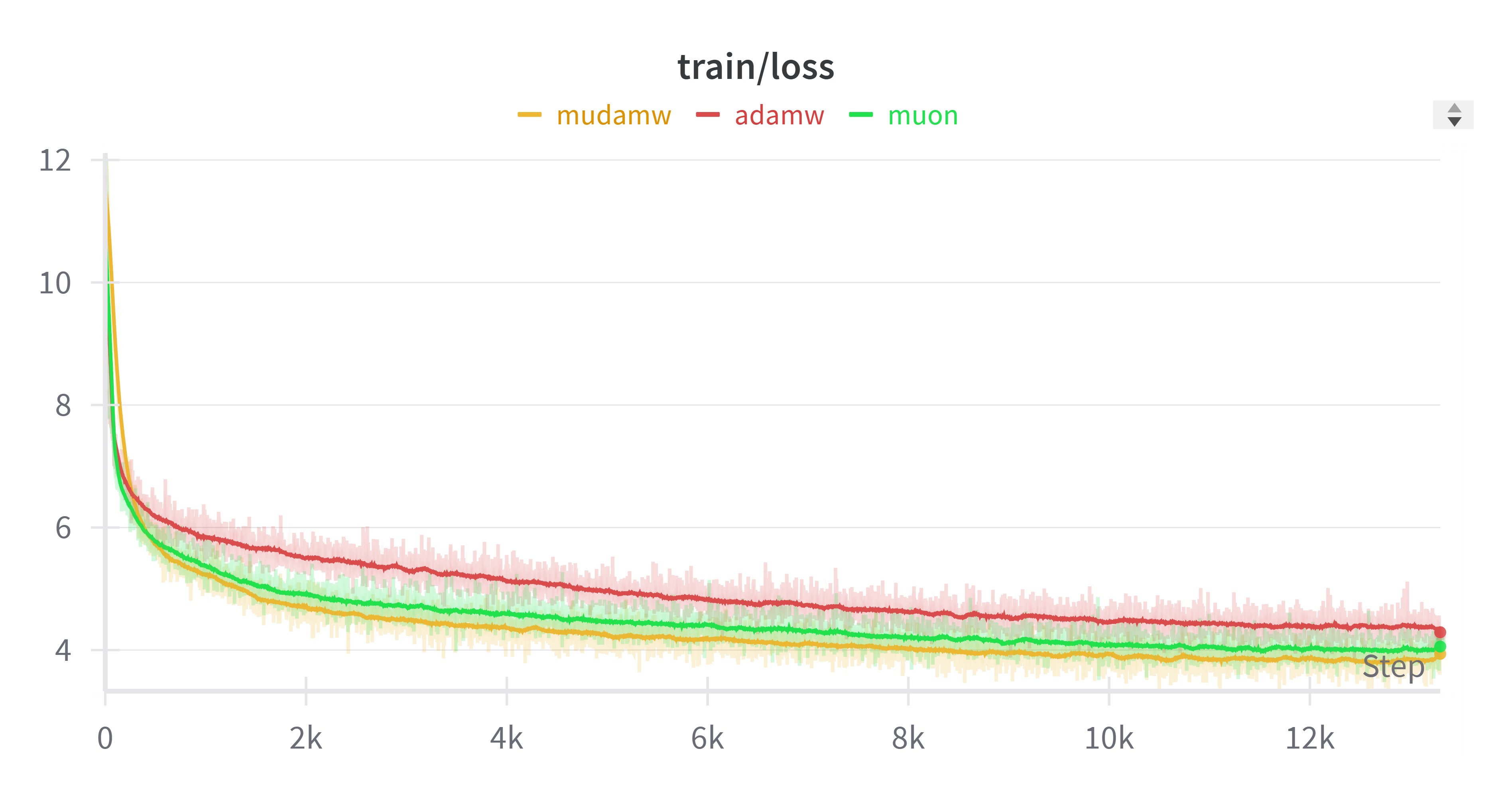
Adam+msgin seems to outperform Muon (image from Twitter @KyleLiang5)
After seeing this, we also tried it on small models and found that we could reproduce similar conclusions! So maybe applying $\mathop{\text{msign}}$ to existing optimizers might offer improved results. The feasibility of this operation is hard to explain within the original Muon framework, but here, understanding it as a limit version of singular value clipping for updates makes it a natural outcome.
Approximate Estimation
It is generally believed that operations related to SVD (Singular Value Decomposition), such as spectral normalization, singular value clipping, or $\mathop{\text{msign}}$, are relatively expensive. Therefore, we still hope to find simpler forms. Since our goal is only to seek scaling laws between model scales, further simplification is indeed possible.
(Note: In fact, our Moonlight work shows that as long as it is implemented well, even performing $\mathop{\text{msign}}$ at every update step adds very limited cost. Therefore, the content of this section is currently aimed more at exploring explicit scaling laws rather than saving computational costs.)
First is still initialization. Initialization is a one-time event, so even if the computation is high, it is not a big issue. Thus, the previous scheme of random initialization followed by spectral normalization/singular value clipping/$\mathop{\text{msign}}$ can be retained. If you still want to refine it further, you can use a statistical result: for a $d_{k-1}\times d_k$ matrix independently sampled from a standard normal distribution, its singular values are roughly $\sqrt{d_{k-1}} + \sqrt{d_k}$. This means that as long as the sampling standard deviation is changed to:
\begin{equation}\sigma_k = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}(\sqrt{d_{k-1}} + \sqrt{d_k})^{-1}\right) = \mathcal{O}\left(\sqrt{\frac{1}{d_{k-1}}\min\left(1, \frac{d_k}{d_{k-1}}\right)}\right) \label{eq:spec-std}\end{equation}
you can satisfy the requirement $\Vert\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$ at the initialization stage. For the proof of this statistical result, you can refer to materials like "High-Dimensional Probability" or "Marchenko-Pastur law", which we will not expand on here.
Next, we examine the update amount, which is slightly more troublesome because the spectral norm of an arbitrary update $\boldsymbol{U}_k$ is not easily estimated. Here, we need to use an empirical conclusion: gradients and updates for parameter weights are usually low-rank. Low-rank here doesn't necessarily mean strictly mathematically low-rank, but rather that the largest few singular values (the count of which is independent of the model scale) significantly exceed the others, making low-rank approximation feasible. This is also the theoretical foundation for various LoRA optimizations.
A direct consequence of this empirical hypothesis is the approximate similarity between the spectral norm and the $F$-norm. Since the spectral norm is the largest singular value, and under the above hypothesis, the $F$-norm is approximately equal to the square root of the sum of squares of the top few singular values, the two are at least consistent in terms of scale, i.e., $\mathcal{O}(\Vert\boldsymbol{U}_k\Vert_2)=\mathcal{O}(\Vert\boldsymbol{U}_k\Vert_F)$. Next, we use the relationship between $\Delta\mathcal{L}$ and $\Delta\boldsymbol{W}_k$:
\begin{equation}\Delta\mathcal{L} \approx \sum_k \langle \Delta\boldsymbol{W}_k, \nabla_{\boldsymbol{W}_k}\mathcal{L}\rangle_F \leq \sum_k \Vert\Delta\boldsymbol{W}_k\Vert_F\, \Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_F\end{equation}
where $\langle\cdot,\cdot\rangle_F$ is the $F$ inner product (treating matrices as flattened vectors). The inequality stems from the Cauchy-Schwarz inequality. Based on the equation above, we have:
\begin{equation}\Delta\mathcal{L} \sim \sum_k \mathcal{O}(\Vert\Delta\boldsymbol{W}_k\Vert_F\, \Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_F) \sim \sum_k \mathcal{O}(\Vert\Delta\boldsymbol{W}_k\Vert_2\, \Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_2)\end{equation}
Don't forget, we already proved earlier that satisfying the two spectral conditions necessarily implies $\Delta\mathcal{L}=\mathcal{O}(1)$. Combining this with the formula above, when $\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$, we have:
\begin{equation}\mathcal{O}(\Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_2) = \mathcal{O}(\Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_F) = \mathcal{O}\left(\sqrt{\frac{d_{k-1}}{d_k}}\right)\label{eq:grad-norm}\end{equation}
This is an important estimation result regarding the magnitude of the gradient. It is derived directly from the two spectral conditions, avoiding explicit gradient calculation. This is the third beautiful aspect of the Spectral Condition: it allows us to obtain relevant estimates without having to calculate gradient expressions via the chain rule.
Learning Rate Strategy
Applying the estimate $\eqref{eq:grad-norm}$ to SGD, i.e., $\Delta \boldsymbol{W}_k = -\eta_k \nabla_{\boldsymbol{W}_k}\mathcal{L}$, according to formula $\eqref{eq:grad-norm}$ we have $\Vert\nabla_{\boldsymbol{W}_k}\mathcal{L}\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_{k-1}}{d_k}}\right)$. To achieve the target $\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$, we need:
\begin{equation}\eta_k = \mathcal{O}\left(\frac{d_k}{d_{k-1}}\right)\label{eq:sgd-eta}\end{equation}
As for Adam, we still use SignSGD to approximate $\Delta \boldsymbol{W}_k = -\eta_k \mathop{\text{sign}}(\nabla_{\boldsymbol{W}_k}\mathcal{L})$. Since $\text{sign}$ is generally $\pm 1$, $\Vert\mathop{\text{sign}}(\nabla_{\boldsymbol{W}_k}\mathcal{L})\Vert_F = \mathcal{O}(\sqrt{d_{k-1} d_k})$. Therefore, to satisfy the target $\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)$, we need:
\begin{equation}\eta_k = \mathcal{O}\left(\frac{1}{d_{k-1}}\right)\label{eq:adam-eta}\end{equation}
Now we can compare the results of the Spectral Condition with muP. muP assumes we are building a model $\mathbb{R}^{d_{in}}\mapsto\mathbb{R}^{d_{out}}$, dividing the model into three parts: first, a $d_{in}\times d$ matrix to project the input to $d$ dimensions; then modeling in the $d$-dimensional space where parameters are $d\times d$ square matrices; and finally, a $d\times d_{out}$ matrix for the $d_{out}$-dimensional output. Correspondingly, muP's conclusions are divided into three parts: input, hidden, and output.
Regarding initialization, muP sets the input variance to $1/d_{in}$, output variance to $1/d^2$, and the remaining parameters to $1/d$. The Spectral Condition, however, has only one formula $\eqref{eq:spec-std}$. But if we look closely, we find that equation $\eqref{eq:spec-std}$ already includes muP's three cases: for an input matrix of size $d_{in}\times d$, substituting into $\eqref{eq:spec-std}$ gives:
\begin{equation}\begin{aligned}
\sigma_{in}^2 =&\, \mathcal{O}\left(\frac{1}{d_{in}}\min\left(1, \frac{d}{d_{in}}\right)\right) = \mathcal{O}\left(\frac{1}{d_{in}}\right) \\
\sigma_k^2 =&\, \mathcal{O}\left(\frac{1}{d}\min\left(1, \frac{d}{d}\right)\right) = \mathcal{O}\left(\frac{1}{d}\right) \\
\sigma_{out}^2 =&\, \mathcal{O}\left(\frac{1}{d}\min\left(1, \frac{d_{out}}{d}\right)\right) = \mathcal{O}\left(\frac{1}{d^2}\right)
\end{aligned}
\qquad(d\to\infty) \end{equation}
Readers might wonder why we only consider $d\to\infty$. This is because $d_{in}$ and $d_{out}$ are task-dependent constants, while the only variable model scale is $d$. muP studies the asymptotic scaling laws of hyperparameters as model scale increases, so it focuses on simplified laws when $d$ is sufficiently large.
Regarding learning rates, for SGD, muP's input learning rate is proportional to $d$, the output learning rate to $1/d$, and the remaining parameters to $1$. The Spectral Condition result $\eqref{eq:sgd-eta}$ similarly covers these three cases. Likewise, for Adam, muP's input learning rate is $1$, output learning rate $1/d$, and hidden parameters $1/d$. The Spectral Condition again describes all three with the single formula $\eqref{eq:adam-eta}$.
Thus, the Spectral Condition achieves richer results than muP in a way that is (in my view) simpler and more elegant. Its more concise results are more meaningful because they don't make overly strong assumptions about the model architecture or parameter shapes. Therefore, I call the Spectral Condition a higher-order version of muP.
Summary
This article introduced the upgraded version of muP—the Spectral Condition. It starts from inequalities related to the spectral norm to analyze the conditions for stable model training, obtaining richer results than muP in a more convenient manner.
\[\left\{\begin{aligned}
&\,\text{Desired Properties:}\left\{\begin{aligned}
&\,\Vert\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1) \\[5pt] &\,\Vert\Delta\boldsymbol{x}_k\Vert_{RMS}=\mathcal{O}(1)
\end{aligned}\right. \\[10pt]
&\,\text{Spectral Condition:}\left\{\begin{aligned}
&\,\Vert\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right) \\[5pt]
&\,\Vert\Delta\boldsymbol{W}_k\Vert_2 = \mathcal{O}\left(\sqrt{\frac{d_k}{d_{k-1}}}\right)
\end{aligned}\right. \\[10pt]
&\,\text{Implementation:}\left\{\begin{aligned}
&\,\text{Spectral Normalization:}\left\{\begin{aligned}
&\,\boldsymbol{W}_k = \sigma\sqrt{\frac{d_k}{d_{k-1}}}\frac{\boldsymbol{W}_k'}{\Vert\boldsymbol{W}_k'\Vert_2} \\[5pt]
&\,\Delta \boldsymbol{W}_k = \eta\sqrt{\frac{d_k}{d_{k-1}}}\frac{\boldsymbol{U}_k}{\Vert\boldsymbol{U}_k\Vert_2}
\end{aligned}\right. \\[10pt]
&\,\text{Singular Value Clipping:}\left\{\begin{aligned}
&\,\boldsymbol{W}_k = \sigma\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{SVC}}(\boldsymbol{W}_k')\xrightarrow{\text{Limit}} \sigma\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{msign}}(\boldsymbol{W}_k')\\[5pt]
&\,\Delta \boldsymbol{W}_k = \eta\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{SVC}}(\boldsymbol{U}_k)\xrightarrow{\text{Limit}} \eta\sqrt{\frac{d_k}{d_{k-1}}}\mathop{\text{msign}}(\boldsymbol{U}_k)
\end{aligned}\right. \\[10pt]
&\,\text{Approximate Estimation:}\left\{\begin{aligned}
&\,\sigma_k = \mathcal{O}\left(\sqrt{\frac{1}{d_{k-1}}\min\left(1, \frac{d_k}{d_{k-1}}\right)}\right) \\[5pt]
&\,\eta_k = \left\{\begin{aligned}
&\,\text{SGD: }\mathcal{O}\left(\frac{d_k}{d_{k-1}}\right) \\[5pt]
&\,\text{Adam: }\mathcal{O}\left(\frac{1}{d_{k-1}}\right)
\end{aligned}\right.
\end{aligned}\right. \\[10pt]
\end{aligned}\right.
\end{aligned}\right.\]