Fine-grained coverage is more precise
By 苏剑林 | May 16, 2025
If Meta's LLAMA series established the standard architecture for Dense models, then DeepSeek might be the founder of the standard MoE architecture. Of course, this doesn't mean DeepSeek invented MoE, nor that its MoE cannot be surpassed. Rather, it means that the improvements DeepSeek proposed for MoE are likely directions where performance gains are significant, gradually becoming the standard configuration for MoE. These include the Loss-Free load balancing scheme introduced in "MoE Travelogue: 3. Another Perspective on Allocation", as well as the Shared Expert and Fine-Grained Expert strategies to be introduced in this article.
When it comes to load balancing, it is undoubtedly a crucial goal for MoE; parts 2–4 of this series have largely centered around it. However, some readers have begun to realize that there is an underlying essential question yet to be answered: Putting aside efficiency requirements, is a uniform distribution necessarily the direction for the best performance? This article takes this question forward to understand Shared Expert and Fine-Grained Expert strategies.
Let's revisit the basic form of MoE: \begin{equation}\boldsymbol{y} = \sum_{i\in \mathop{\text{argtop}}_k \boldsymbol{\rho}} \rho_i \boldsymbol{e}_i\end{equation} In addition to this, the Loss-Free method in "MoE Travelogue: 3. Another Perspective on Allocation" replaces $\mathop{\text{argtop}}_k \boldsymbol{\rho}$ with $\mathop{\text{argtop}}_k \boldsymbol{\rho}+\boldsymbol{b}$, and in "MoE Travelogue: 4. Invest More at Difficulties", we generalized it to $\mathop{\text{argwhere}} \boldsymbol{\rho}+\boldsymbol{b} > 0$. However, these variants are orthogonal to the Shared Expert technique, so we will only use the basic form as an example below.
Shared Expert modifies the above equation to: \begin{equation}\boldsymbol{y} = \sum_{i=1}^s \boldsymbol{e}_i + \sum_{i\in \mathop{\text{argtop}}_{k-s} \boldsymbol{\rho}_{[s:]}} \rho_{i+s} \boldsymbol{e}_{i+s}\label{eq:share-1}\end{equation} In other words, the original "$n$ choose $k$" is changed to "$n-s$ choose $k-s$", and $s$ additional Experts are necessarily selected. These are called "Shared Experts" (which we jokingly referred to as "Permanent Council Members" when they first appeared), while the remaining $n-s$ Experts are called "Routed Experts." Usually, the number of Shared Experts $s$ is not very large—typically 1 or 2—as too many might cause the model to "neglect" the remaining Routed Experts.
It should be noted that before and after enabling Shared Experts, the total number of Experts remains $n$ and the number of activated Experts is still $k$. Therefore, in principle, Shared Experts do not increase the model's parameter count or inference cost. Despite this, DeepSeekMoE and some of our own experiments show that Shared Experts can still improve model performance to some extent.
We can understand Shared Experts from multiple perspectives. For instance, from a residual perspective, the Shared Expert technique actually changes learning each Expert into learning its residual relative to the Shared Experts. This reduces learning difficulty and provides better gradients. In DeepSeek's words: by compressing common knowledge into these Shared Experts, redundancy between Routed Experts is reduced, improving parameter efficiency and ensuring each Routed Expert focuses on unique aspects.
If we compare Routed Experts to subject teachers in a middle school, then Shared Experts are like the "Class Teacher" (homeroom teacher). If a class only had subject teachers, each would inevitably be burdened with some management work. Setting a Class Teacher role concentrates these common management tasks onto one person, allowing subject teachers to focus on their specific teaching, thereby improving efficiency.
It can also be understood geometrically. Inevitable commonalities between Experts mean the geometric angle between their vectors is less than 90 degrees, which contradicts the "pairwise orthogonal" assumption of Expert vectors used in "MoE Travelogue: 1. Starting from Geometric Significance". Although it can be understood as an approximate solution when this assumption doesn't hold, the closer it is to being true, the better. We can understand Shared Experts as the mean of these Routed Experts; by learning the residuals after subtracting the mean, the orthogonality assumption becomes easier to satisfy.
We can write Equation \eqref{eq:share-1} more generally as: \begin{equation}\boldsymbol{y} = \sum_{i=1}^s \boldsymbol{e}_i + \lambda\sum_{i\in \mathop{\text{argtop}}_{k-s} \boldsymbol{\rho}_{[s:]}} \rho_{i+s} \boldsymbol{e}_{i+s}\end{equation} Since Routed Experts have weights $\rho_{i+s}$ while Shared Experts do not, and because the number of Routed Experts is usually much larger than the number of Shared Experts ($n - s \gg s$), their proportions might become imbalanced. Therefore, to ensure neither is buried by the other, setting a reasonable $\lambda$ is particularly important. Regarding this, in "Muon is Scalable for LLM Training", we proposed that an appropriate $\lambda$ should make the norms of both components approximately equal during initialization.
Specifically, we assume each Expert has the same norm at initialization (without loss of generality, we can set it to 1) and that they are pairwise orthogonal. Then, assuming the Router's logits follow a standard normal distribution (zero mean, unit variance—though other variances can be considered if necessary), the total norm of the $s$ Shared Experts is $\sqrt{s}$, while the total norm of the Routed Experts is: \begin{equation}\lambda\sqrt{\sum_{i\in \mathop{\text{argtop}}_{k-s} \boldsymbol{\rho}_{[s:]}} \rho_{i+s}^2}\end{equation} By setting this equal to $\sqrt{s}$, we can estimate $\lambda$. Due to choices regarding activation functions and whether to re-normalize, the Router differences in various MoEs can be quite large. Thus, we don't try to find an analytical solution but instead use numerical simulation:
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
return (p := np.exp(x)) / p.sum()
def scaling_factor(n, k, s, act='softmax', renorm=False):
factors = []
for _ in range(10000):
logits = np.random.randn(n - s)
p = np.sort(eval(act)(logits))[::-1][:k - s]
if renorm:
p /= p.sum()
factors.append(s**0.5 / (p**2).sum()**0.5)
return np.mean(factors)
print(scaling_factor(162, 8, 2, 'softmax', False))
print(scaling_factor(257, 9, 1, 'sigmoid', True))Quite coincidentally, the simulation results of this script match the settings of DeepSeek-V2 and DeepSeek-V3 very closely. For DeepSeek-V2, $n=162, k=8, s=2$, with Softmax activation and no re-normalization; the script's simulation result is approximately 16, which is exactly DeepSeek-V2's $\lambda$ [Source]. For DeepSeek-V3, $n=257, k=9, s=1$, with Sigmoid activation and re-normalization; the result is about 2.83, while DeepSeek-V3's $\lambda$ is 2.5 [Source].
Back to the question at the beginning: Is balance necessarily the direction for the best performance? It seems Shared Expert provides a reference answer: Not necessarily. Because Shared Experts can be understood as certain Experts being definitely activated, overall, this leads to a non-uniform distribution of Experts: \begin{equation}\boldsymbol{F} = \frac{1}{s+1}\bigg[\underbrace{1,\cdots,1}_{s \text{ items}},\underbrace{\frac{1}{n-s},\cdots,\frac{1}{n-s}}_{n-s \text{ items}}\bigg]\end{equation} In fact, non-uniform distributions are ubiquitous in the real world, so it should be easy to accept that a uniform distribution is not the optimal direction. Using the middle school teacher analogy again: the number of teachers in different subjects at the same school is usually not uniform. Languages, Math, and English teachers are typically the most numerous, followed by Physics, Chemistry, and Biology, with PE and Art being the fewest (and they often "call in sick"). For more examples of non-uniform distributions, you can search for Zipf's Law.
In short, the non-uniformity of the real world inevitably leads to the non-uniformity of natural language, which in turn leads to the non-optimality of uniform distribution. Of course, from a training perspective, a uniform distribution is easier to parallelize and scale. Therefore, isolating a portion as Shared Experts while still wishing the remaining Routed Experts to be uniform is a trade-off that is friendly to both sides, rather than directly forcing Routed Experts to align with a non-uniform distribution.
That was about training; what about inference? In the inference phase, the actual distribution of Routed Experts can be predicted in advance. Since backpropagation is not considered, if optimized carefully, it is theoretically possible to achieve no drop in efficiency. However, since current MoE inference infrastructure is designed for uniform distributions and limited by hardware constraints like single-card VRAM, we still hope for Routed Experts to be uniform to achieve better inference efficiency.
In addition to Shared Experts, another improvement mentioned in DeepSeekMoE is Fine-Grained Experts. It points out that when the total parameter count and activated parameter count are fixed, the finer the granularity of the Experts, the better the performance tends to be.
For example, if we originally had an "$n$ choose $k$" Routed Expert setup, and we now halve the size of each Expert and switch to "$2n$ choose $2k$", the total parameters and activated parameters remain the same, but the latter often performs better. The original paper states that this enriches the diversity of Expert combinations, i.e., \begin{equation}\binom{n}{k} \ll \binom{2n}{2k} \ll \binom{4n}{4k} \ll \cdots\end{equation} Of course, we can have other interpretations. For instance, by further dividing Experts into smaller units, each Expert can focus on a narrower domain of knowledge, achieving finer knowledge decomposition. However, note that Fine-Grained Experts are not cost-free. As $n$ increases, the load between Experts often becomes more imbalanced, and the communication and coordination costs between Experts also increase. Thus, $n$ cannot increase infinitely; there is a "comfort zone" where both effects and efficiency are balanced.
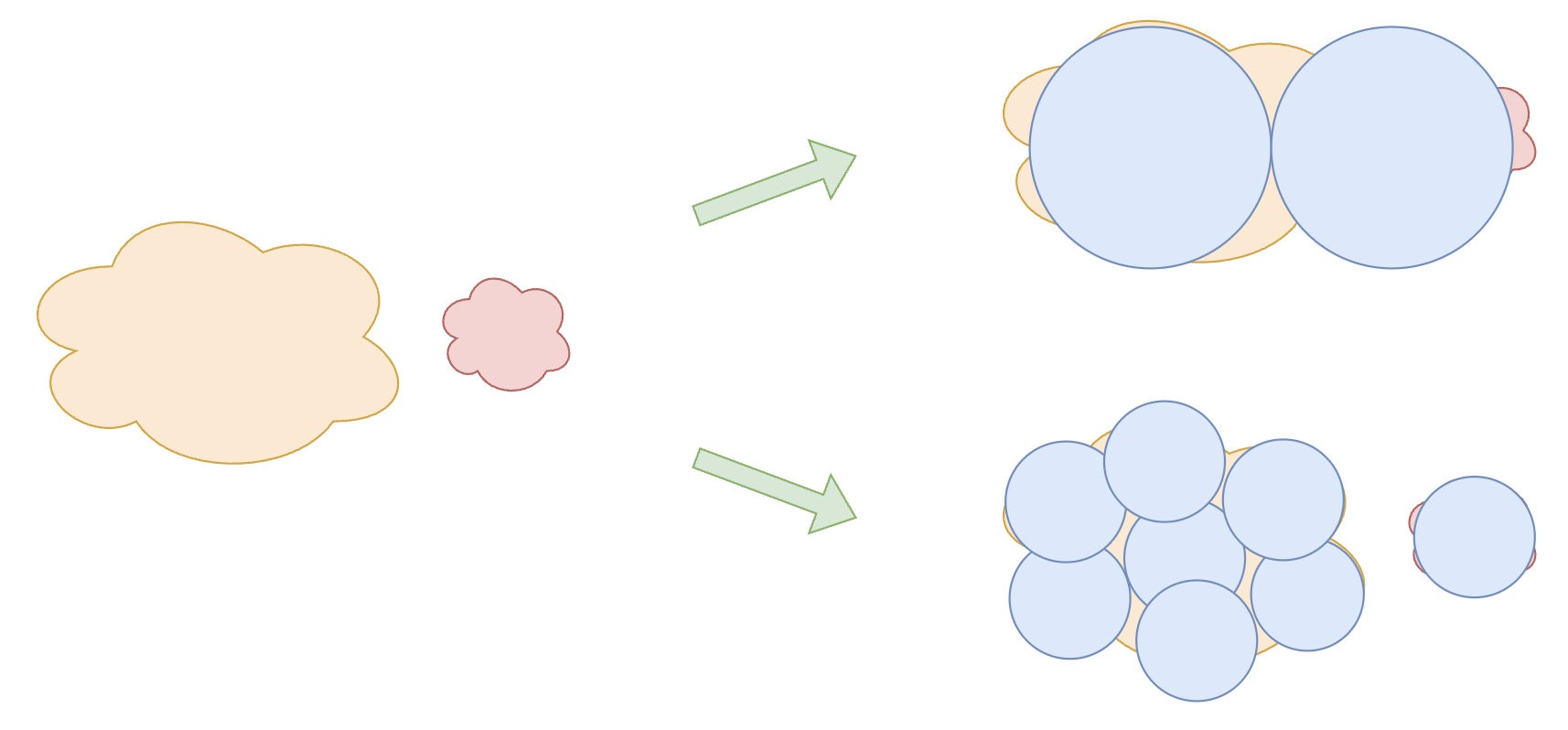
Regarding the effectiveness of Fine-Grained Experts, I propose another explanation that is not easily noticed, related to the theme of this article: A larger number of finer-grained Experts can better simulate the non-uniformity of the real world. For example, in the figure below, suppose knowledge can be divided into a large and a small category, and each Expert is a circle. If we use 2 large circles to cover them, there will be certain omissions and waste. If we instead use 8 small circles with the same total area, we can cover them more precisely, resulting in better performance.
Fine-grained coverage is more precise
This article introduced the Shared Expert and Fine-Grained Expert strategies in MoE and pointed out that they both, to some extent, reflect the non-optimality of load balancing.