By 苏剑林 | June 22, 2015
Foreword: Back in April and May, I participated in two data mining competitions: the "Liangjian Cup" organized by the School of Physics and Telecommunication Engineering, and the 3rd "Teddy Cup" National Undergraduate Data Mining Competition. Coincidentally, in both competitions, one problem primarily involved Chinese sentiment classification work. When doing the "Liangjian Cup," as I was a novice with limited skills, I only implemented a simple text sentiment classification model based on traditional ideas. In the subsequent "Teddy Cup," through deeper study, I had basic knowledge of deep learning concepts and implemented a text sentiment classification model using deep learning algorithms. Therefore, I plan to post both models on my blog for readers' reference. Beginners can use them to compare the differences between the two and understand the relevant approaches. Experts are welcome to pass by with a smile.
Based on Sentiment Dictionary
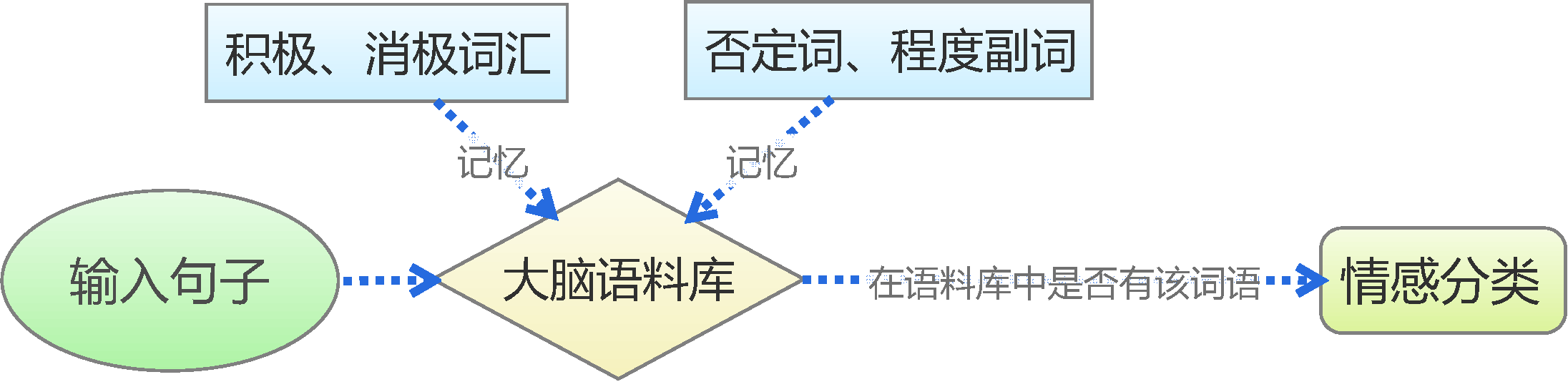
Simple human judgment thinking
Traditional text sentiment classification based on sentiment dictionaries is the simplest simulation of human memory and judgment thinking, as shown in the figure above. First, we learn and memorize some basic vocabulary, such as negation words like "not," positive words like "like" and "love," and negative words like "dislike" and "hate," thereby forming a basic corpus in our minds. Then, we perform a direct breakdown of the input sentence to see if the words memorized in our vocabulary list exist, and then judge the sentiment based on the category of these words. For instance, in "I like math," the word "like" is in our memorized positive vocabulary list, so we judge it as having positive sentiment.
Based on this idea, we can implement sentiment dictionary-based text sentiment classification through several steps: preprocessing, tokenization, training (loading) the sentiment dictionary, and judgment, as illustrated in the following diagram. The raw materials used to test the model include comments on Mengniu milk provided by Teacher Xue Yun and mobile phone comment data purchased online (see attachment).

Text sentiment classification based on sentiment dictionary
Text Preprocessing
Original corpora crawled by web crawlers usually contain unnecessary information, such as extra HTML tags, so preprocessing is required. The Mengniu milk comments provided by Teacher Xue Yun were no exception. Our team used Python as our preprocessing tool, utilizing libraries like Numpy and Pandas, with regular expressions as the primary text tool. After preprocessing, the raw corpus was standardized into the following table, where we used -1 to label negative sentiment comments and 1 for positive sentiment comments.
\[\begin{array}{c|c|c}
\hline
& \text{comment} & \text{mark}\\
\hline
0 & \text{Mengniu goes out to embarrass themselves again} & -1\\
1 & \text{Cherish life, stay away from Mengniu} & -1\\
\vdots & \vdots & \vdots \\
1171 & \text{I have always loved drinking Mengniu pure milk, always, very much} & 1\\
1172 & \text{Giving Mengniu... health is the best gift.} & 1\\
\vdots & \vdots & \vdots \\
\hline
\end{array}\]
Automatic Sentence Segmentation
To determine if a sentence contains corresponding words from the sentiment dictionary, we need to accurately cut the sentence into individual words, which is automatic segmentation. We compared existing segmentation tools and, considering accuracy and ease of use on the Python platform, ultimately chose "Jieba Chinese Segmentation" as our tool.
The table below shows the segmentation results of common tools on a typical test sentence:
Test Sentence: 工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作 (The female secretary of the Industry and Information Technology Office passes through the subordinate departments every month to personally explain the installation work of 24-port switches and other technical components.)
| Segmentation Tool |
Test Result |
| Jieba Segmentation |
工信处/ 女干事/ 每月/ 经过/ 下属/ 科室/ 都/ 要/ 亲口/ 交代/ 24/ 口/ 交换机/ 等/ 技术性/ 器件/ 的/ 安装/ 工作 |
| ICTCLAS (CAS) |
工/n 信/n 处女/n 干事/n 每月/r 经过/p 下属/v 科室/n 都/d 要/v 亲口/d 交代/v 24/m 口/q 交换机/n 等/udeng 技术性/n 器件/n 的/ude1 安装/vn 工作/vn |
| smallseg |
工信/ 信处/ 女干事/ 每月/ 经过/ 下属/ 科室/ 都要/ 亲口/ 交代/ 24/ 口/ 交换机/ 等/ 技术性/ 器件/ 的/ 安装/ 工作 |
| Yaha Segmentation |
工信处 / 女 / 干事 / 每月 / 经过 / 下属 / 科室 / 都 / 要 / 亲口 / 交代 / 24 / 口 / 交换机 / 等 / 技术性 / 器件 / 的 / 安装 / 工作 |
Loading the Sentiment Dictionary
Generally, the dictionary is the core part of text mining, and sentiment classification is no exception. The sentiment dictionary is divided into four parts: positive sentiment dictionary, negative sentiment dictionary, negation dictionary, and degree adverb dictionary. To obtain a more complete dictionary, we collected several sentiment dictionaries from the internet, integrated and deduplicated them, and adjusted some words to achieve the highest possible accuracy.
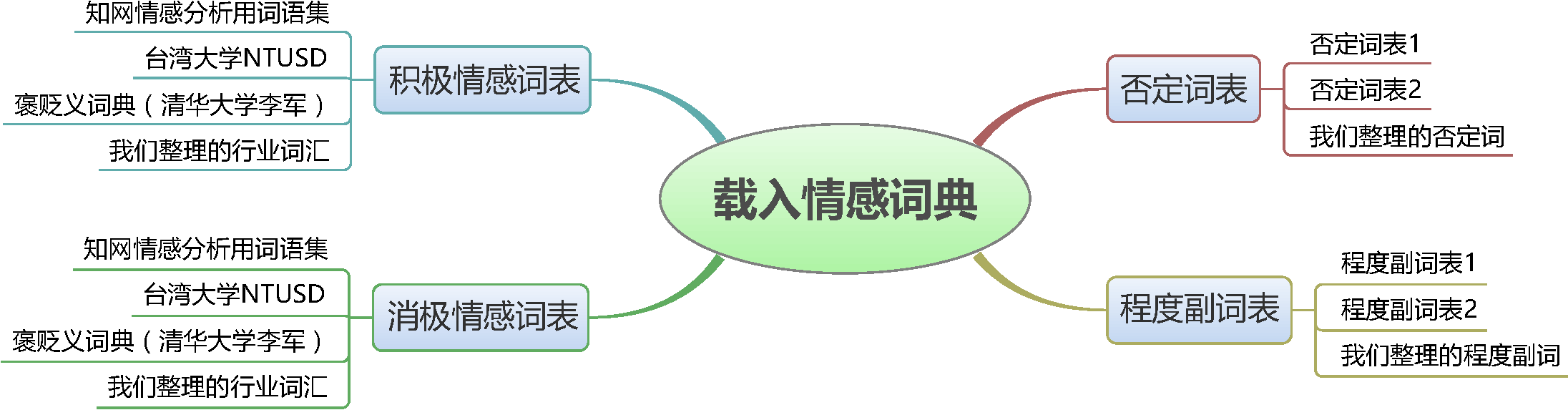
Building a sentiment dictionary
Our team did not simply integrate dictionaries collected online; we also specifically and purposefully cleaned and updated the dictionary. In particular, we added some industry-specific vocabulary to increase the hit rate in classification. Different industries have significant differences in the frequency of certain words, and these words might be key terminology for sentiment classification. For example, the comment data for Mengniu milk belongs to the food and beverage industry; in this industry, words like "eat" and "drink" appear frequently and are usually positive evaluations, while "don't eat" or "don't drink" usually imply negative evaluations. In other industries, these words might not have a clear sentiment orientation. Another example is the mobile phone industry, where phrases like "this phone is very drop-resistant and waterproof"—"drop-resistant" and "waterproof"—are positive sentiment words in that specific domain. Thus, it is necessary to consider these factors in the model.
Text Sentiment Classification
Text sentiment classification based on a sentiment dictionary is relatively mechanical. For simplicity, we assign a weight of 1 to each positive sentiment word and -1 to each negative sentiment word, assuming that sentiment values satisfy the principle of linear superposition. We then segment the sentence; if the word vector contains a corresponding word, we add the weight. Negation words and degree adverbs have special judgment rules: negation words cause the weight to flip sign, and degree adverbs double the weight. Finally, the sentiment of the sentence is judged based on whether the total weight is positive or negative. The basic algorithm is shown in the figure.
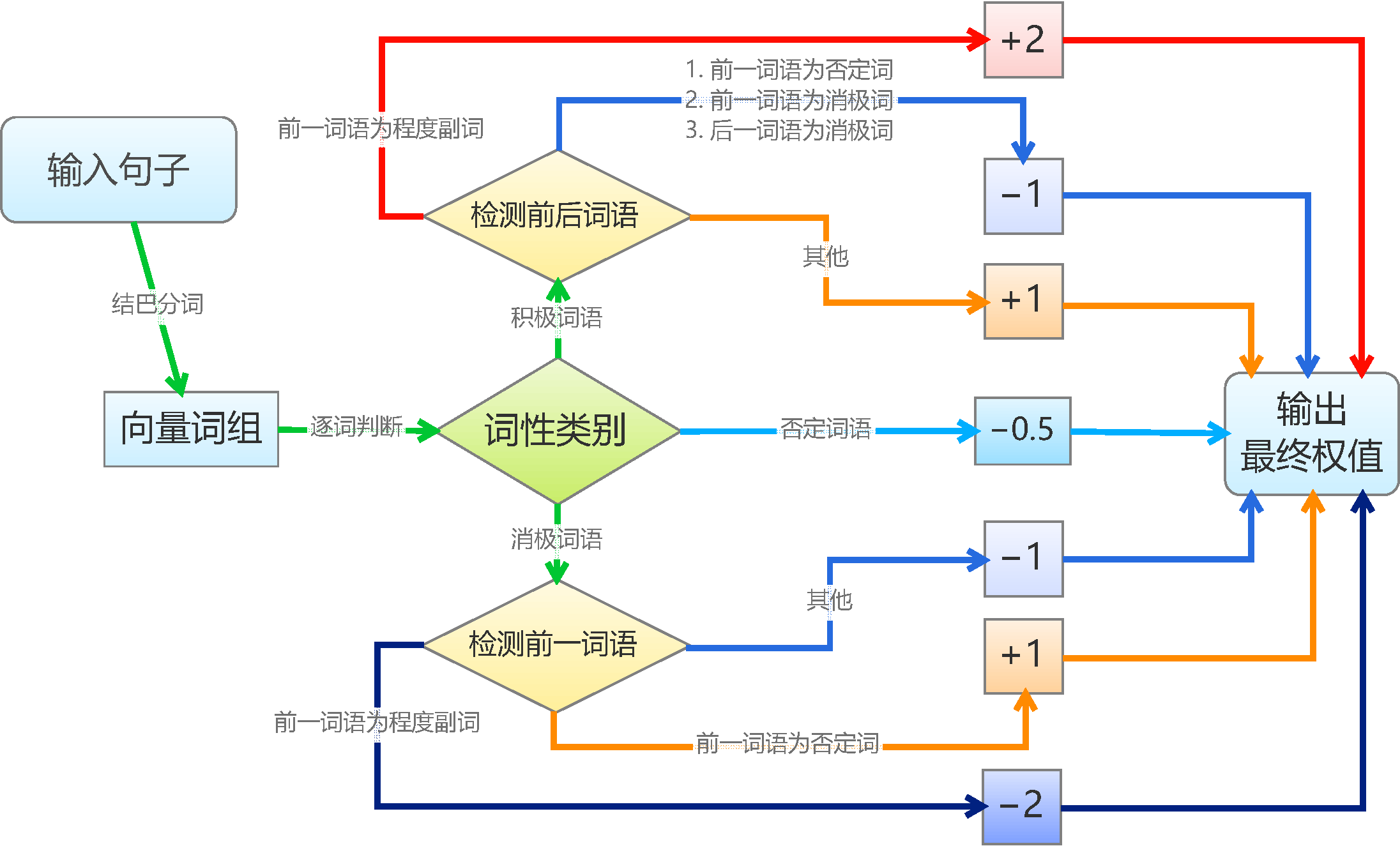
Text classification based on sentiment dictionary - flowchart
It should be noted that for programming and testing feasibility, we made several assumptions (simplifications). Assumption 1: We assume all positive and negative words have equal weights. This only holds in simple judgment cases; for more precise classification, it is clearly incorrect (e.g., "hate" is more severe than "dislike"). A way to fix this is to assign different weights to each word, which we will discuss in the second part of this series. Assumption 2: We assume weights are linearly superimposed. This holds in most cases, but in the second part, we will explore introducing nonlinearity to enhance accuracy. Assumption 3: For negations and degree adverbs, we just used simple sign inversion and doubling. In reality, different negation words and degree adverbs have different weights (e.g., "like very much" is deeper than "quite like"), but we did not make that distinction.
As for the algorithm's implementation, we chose Python. With Python's rich extension support, we implemented all the steps in fewer than a hundred lines of code, resulting in an effective sentiment classification algorithm, which fully reflects Python's conciseness. Below, we test the effectiveness of our algorithm.
Model Results Testing
As a basic test, we first applied our model to the Mengniu milk comments provided by Teacher Xue Yun. The results were satisfying, reaching an accuracy of 82.02%. The detailed test report is in the table below:
\[\begin{array}{c|c|c|c|c|c}
\hline
\text{Data Content} & \text{Pos Samples} & \text{Neg Samples} & \text{Accuracy} & \text{TPR} & \text{TNR}\\
\hline
\text{Milk Comments} & 1005 & 1170 & 0.8202 & 0.8209 & 0.8197\\
\hline
\end{array}\]
(Where positive samples are positive sentiment comments, and negative samples are negative sentiment data.)
\[\begin{aligned}
&\text{Accuracy}=\frac{\text{Correctly predicted samples}}{\text{Total samples}}\\
&\text{True Positive Rate (TPR)}=\frac{\text{Positive samples predicted as positive}}{\text{Total positive samples}}\\
&\text{True Negative Rate (TNR)}=\frac{\text{Negative samples predicted as negative}}{\text{Total negative samples}}
\end{aligned}\]
To our surprise, the model adjusted from the Mengniu milk comment data reached 81.96% accuracy when applied directly to sentiment classification for a certain mobile phone's comment data! This indicates our model has good robustness and can perform well across different industries' comment data.
\[\begin{array}{c|c|c|c|c|c}
\hline
\text{Data Content} & \text{Pos Samples} & \text{Neg Samples} & \text{Accuracy} & \text{TPR} & \text{TNR}\\
\hline
\text{Phone Comments} & 1158 & 1159 & 0.8196 & 0.7539 & 0.8852\\
\hline
\end{array}\]
Conclusion: Our team preliminary implemented text sentiment classification based on a sentiment dictionary. Test results show that simple judgment rules can give this algorithm good accuracy and robustness. Generally, a model with over 80% accuracy is considered to have production value suitable for industrial environments. Clearly, our model has initially reached this standard.
Difficulties
After two tests, we can tentatively conclude that our model's accuracy basically reaches over 80%. Furthermore, some mature commercial programs only reach about 85% to 90% accuracy (such as BosonNLP). This shows that our simple model has indeed achieved satisfactory results; on the other hand, this fact also indicates that the performance of the traditional "sentiment dictionary-based text sentiment classification" model has limited room for improvement. This is due to the inherent complexity of text sentiment classification. After preliminary discussion, we believe the difficulties lie in the following areas:
The language system is extremely complex
Ultimately, this is because the language system in our brains is extremely complex. (1) We are performing text sentiment classification. Text and text sentiment are products of human culture; in other words, humans are the only accurate standard for judgment. (2) Human language is a complex cultural product; a sentence is not a simple linear combination of words—it contains significant nonlinearity. (3) When we describe a sentence, we view it as a whole rather than a set of words. Different combinations, orders, and numbers of words can bring different meanings and sentiments, leading to difficulties in sentiment classification.
Therefore, text sentiment classification is essentially a simulation of human brain thinking. Our previous model is essentially the simplest simulation. However, what we simulated were just simple mental sets. True sentiment judgment isn't a set of simple rules but a complex network.
The brain does more than just sentiment classification
In fact, when we judge the sentiment of a sentence, we are not just thinking about the sentiment; we also judge the sentence type (imperative, interrogative, or declarative?). When we consider each word in a sentence, we don't just focus on positive, negative, negation, or degree words; we focus on every word (subject, predicate, object, etc.), forming a holistic understanding of the sentence. We even connect the context to judge. These judgments might be unconscious, but the brain does them to form a complete understanding before making an accurate sentiment judgment. That is, our brain is in fact a very high-speed and complex processor; while we want to do sentiment classification, the brain simultaneously performs many other tasks.
Living Water: Learning and Prediction
A distinctive feature that separates humans from machines (and even humans from other animals) is the consciousness and ability to learn. Besides being taught by others, we acquire new knowledge through our own learning, summarization, and guessing. Sentiment classification is no exception; we don't just memorize a large number of sentiment words—we also summarize or infer new ones. For example, if we only know "like" and "love" are positive, we will guess that "fondness" also has a positive sentiment. This learning ability is an important way we expand our vocabulary and optimize our memory patterns (i.e., we don't need to specifically cram every word into the brain's corpus; we only need to remember "like" and "love" and assign a connection to obtain "fondness").
Optimization Ideas
Through the above analysis, we see the intrinsic complexity of text sentiment classification and several characteristics of how the human brain performs classification. Based on this, we propose the following improvement measures.
Introduction of Nonlinear Features
As mentioned earlier, real human sentiment classification is heavily nonlinear, and models based on simple linear combinations have limited performance. Therefore, to improve accuracy, it is necessary to introduce nonlinearity into the model.
Nonlinearity refers to the new semantics formed by the combination of words. In fact, our preliminary model already simply introduced nonlinearity—we treated cases where a positive word and a negative word were adjacent as a combined negative phrase and assigned it a negative weight. More refined combination weights can be achieved through a "Dictionary Matrix." We place all known positive and negative words into the same set, number them, and record the weights of word pairs using the following "Dictionary Matrix":
\[\begin{array}{c|cccccc}
\text{Word} & \text{(Null)} & \text{Like} & \text{Love} & \dots & \text{Hate} & \dots\\
\hline
\text{(Null)} & 0 & 1 & 2 & \dots & -1 & \dots\\
\text{Like} & 1 & 2 & 3 & \dots & -2 & \dots\\
\text{Love} & 2 & 3 & 4 & \dots & -2 & \dots\\
\vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \dots\\
\text{Hate} & -1 & -2 & -3 & \dots & -2 & \dots\\
\vdots & \vdots & \vdots & \vdots & \vdots & \vdots & \dots
\end{array}\]
Not every word combination is valid, but we can still calculate combination weights. The calculation of sentiment weights can be found in the references. However, the number of sentiment words is very large, and the number of elements in the dictionary matrix is its square, resulting in massive data. This enters the realm of "Big Data." To efficiently implement nonlinearity, we need to explore optimization schemes for word combinations, including construction, storage, and indexing schemes.
Automatic Expansion of the Sentiment Dictionary
In today's internet age, new words appear like spring mushrooms, including "newly constructed internet terms" and "giving existing words new meanings." On the other hand, the sentiment dictionaries we organize cannot possibly contain all existing sentiment words. Therefore, automatic expansion of the sentiment dictionary is a necessary condition for maintaining the timeliness of sentiment classification models. Currently, using web crawlers, we can collect large amounts of comment data from Weibo and communities. To find new words with sentiment orientation from this mass of data, our approach uses unsupervised word frequency statistics.
Our goal is "automatic expansion." Thus, we aim to perform unsupervised learning based on the current model to complete the dictionary expansion, thereby enhancing the model's performance, and then iterate in the same way. This is a positive feedback adjustment process. Although we can crawl a large number of comments, they are unlabeled. We use the existing model to classify the sentiment of the comment data, then count word frequencies in the same category of sentiment (positive or negative) collections, and finally compare frequencies across the positive and negative sets. If a word appears very infrequently in positive comments but very frequently in negative ones, we can confidently add it to the negative sentiment dictionary or assign it a negative weight.
For example, suppose "shady" is not in our negative dictionary, but basic words like "vile," "dislike," "resent," and "like" already exist. Then we can correctly classify the following sentences:
\[\begin{array}{c|c}
\hline
\text{Sentence} & \text{Weight}\\
\hline
\text{This shady boss is so vile} & -2\\
\hline
\text{I resent the practices of this shady enterprise} & -2\\
\hline
\text{Dislike this shady shop very much} & -2\\
\hline
\text{This shop is really shady!} & 0\\
\hline
\vdots & \vdots\\
\hline
\end{array}\]
Since "shady" is not in the negative dictionary, "This shop is really shady!" would be judged as neutral (weight 0). After classification, we count the word frequencies for positive and negative labels. We find that the new word "shady" appears many times in negative comments but almost never in positive ones. We then add "shady" to our negative sentiment dictionary and update our results:
\[\begin{array}{c|c}
\hline
\text{Sentence} & \text{Weight}\\
\hline
\text{This shady boss is so vile} & -3\\
\hline
\text{I resent the practices of this shady enterprise} & -3\\
\hline
\text{Dislike this shady shop very much} & -3\\
\hline
\text{This shop is really shady!} & -2\\
\hline
\vdots & \vdots\\
\hline
\end{array}\]
Thus, we expanded the dictionary through unsupervised learning, improved accuracy, and enhanced model performance. This is an iterative process where previous results help the subsequent steps.
Conclusion of this paper:
Text sentiment classification based on a sentiment dictionary is easy to implement; its core lies in the training (compilation) of the sentiment dictionary.
The language system is extremely complex; dictionary-based classification is just a linear model, and its performance is limited.
Properly introducing nonlinear features into text sentiment classification can effectively improve model accuracy.
Introducing an unsupervised learning mechanism for dictionary expansion can effectively discover new sentiment words, ensuring the model's robustness and timeliness.
References
Deep Learning Study Notes: http://blog.csdn.net/zouxy09/article/details/8775360
Yoshua Bengio, Réjean Ducharme Pascal Vincent, Christian Jauvin. A Neural Probabilistic Language Model, 2003
A New Language Model: http://blog.sciencenet.cn/blog-795431-647334.html
Sentiment Analysis Dataset for Comment Data: http://www.datatang.com/data/11857
"Jieba" Chinese Segmentation: https://github.com/fxsjy/jieba
NLPIR Chinese Segmentation System: http://ictclas.nlpir.org/
smallseg: https://code.google.com/p/smallseg/
yaha segmentation: https://github.com/jannson/yaha
Sentiment Word Set (beta): http://www.keenage.com/html/c_bulletin_2007.htm
NTUSD - Simplified Chinese Sentiment Polarity Dictionary: http://www.datatang.com/data/11837
Degree Adverbs, Intensities, and Negation Word List: http://www.datatang.com/data/44198
Summary of Existing Sentiment Dictionaries: http://www.datatang.com/data/46922
BosonNLP: http://bosonnlp.com/product
Implementation Platform
The programming tools used by our team were tested in the following environment:
Windows 8.1 Microsoft Operating System.
Python 3.4 Development platform/language. Version 3.x was chosen over 2.x primarily for better support for Chinese characters.
Numpy A numerical calculation library for Python, providing fast processing for multi-dimensional arrays.
Pandas A data analysis package for Python.
Jieba Segmentation A Chinese segmentation tool for Python, also available in Java, C++, Node.js, etc.
Code List
Resources: Sentiment Polarity Dictionary.zip
Preprocessing
# (Python code for preprocessing goes here)
Loading Sentiment Dictionary
# (Python code for loading dictionary goes here)
Prediction Function
# (Python code for prediction function goes here)
Simple Test
# (Python code for simple testing goes here)