By 苏剑林 | August 22, 2016
About the Character Labeling Method
The previous article discussed the character labeling method for word segmentation. It is important to note that the character labeling method has great potential; otherwise, it would not have achieved top results in public tests. In my view, there are two main reasons why character labeling is effective. The first reason is that it transforms the word segmentation problem into a sequence labeling problem, and this labeling is aligned—meaning the input characters and output labels have a one-to-one correspondence, which is a mature problem in sequence labeling. The second reason is that this labeling method is actually a process of summarizing semantic patterns. Taking 4-tag labeling as an example, we know that the character "李" (Li) is a common surname and often serves as the first character of a multi-character word (a person's name), thus it is labeled as 'b'. Similarly, "想" (Xiang), due to words like "理想" (ideal), has a high proportion of being labeled as 'e'. Consequently, when "李想" appear together, even if the word "李想" is not in the original lexicon, we can correctly output 'be', thereby identifying "李想" as a word. It is precisely for this reason that even the HMM model, often regarded as the least precise, can produce good results.
Regarding labeling, there is another topic worth discussing: the number of tags. Commonly used is the 4-tag system; in fact, there are also 6-tag and 2-tag systems. The simplest way to mark segmentation results would be 2-tag, i.e., marking "split/don't split," but the effectiveness is poor. Why does a higher number of tags actually yield better results? Because more tags actually provide a more comprehensive summary of semantic patterns. For example, with 4-tag labeling, we can summarize which characters form words on their own, which are frequently used as beginnings, and which are used as endings. However, with only 2-tag labeling, one can only summarize which characters frequently serve as beginnings, which is insufficient from an inductive perspective. But how does 6-tag compare to 4-tag? I don't think it is necessarily better. 6-tag means summarizing which characters act as the second or third character, but is this summarized angle correct? I feel that there are few characters fixed specifically for the second or third position; the generalizability of this pattern is much weaker than the patterns for initial and final characters (though from a new word discovery perspective, 6-tag makes it easier to find long words).
Bidirectional LSTM
Regarding Bidirectional LSTM, the way to understand it is: Bidirectional LSTM is an improvement over LSTM, and LSTM is an improvement over RNN. Therefore, one first needs to understand RNN.
In my humble work "From Boosting Learning to Neural Networks: Is Looking at a Mountain still Looking at a Mountain?", I mentioned that the output results of a model can, in fact, be viewed as a type of feature and can also be used as input for the model. RNN is precisely such a network structure. Ordinary multi-layer neural networks are a one-way propagation process from input to output. If high-dimensional inputs are involved, this could be done, but there are too many nodes, making it difficult to train and prone to overfitting. For example, if an image input is 1000x1000, it is difficult to process directly, which led to CNNs; or a sentence of 1000 words, where each word uses a 100-dimensional word vector, the input dimension is also not small. In this case, one solution to the problem is RNN (CNNs can also be used, but RNNs are more suitable for sequence problems).
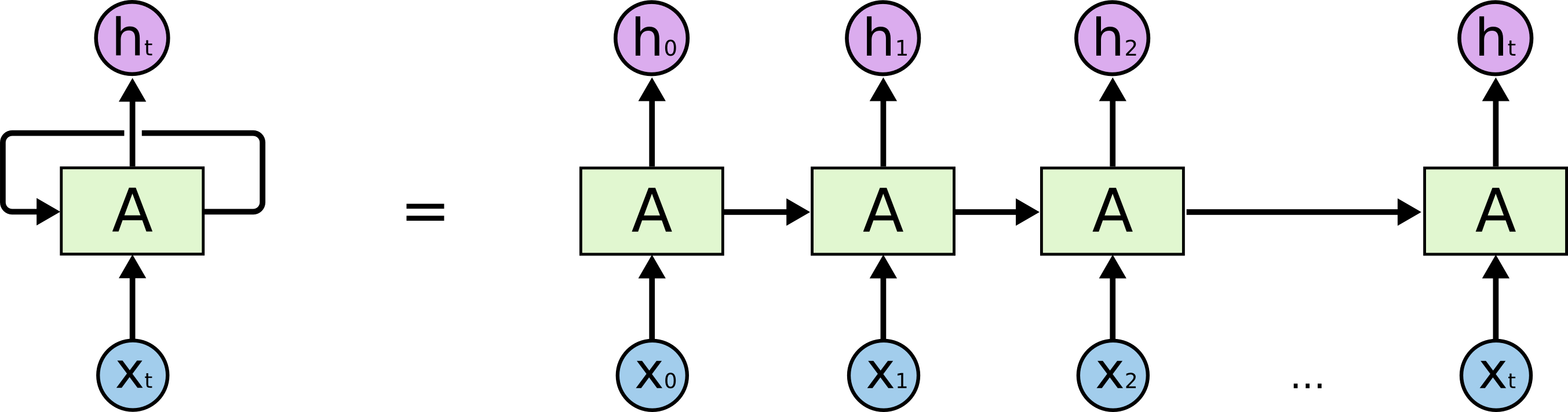
The RNN Process
The meaning of RNN is that in order to predict the final result, I first use the first word to make a prediction. Of course, a prediction using only the first word will not be precise. I take this result as a feature and use it together with the second word to predict the result; next, I use this new prediction result combined with the third word to make a new prediction; then I repeat this process until the last word. Thus, if there are n words in the input, we actually perform n predictions and provide n prediction sequences. Throughout the process, the model shares a single set of parameters. Therefore, RNN reduces the number of model parameters, preventing overfitting. At the same time, it is inherently designed for sequence problems and is thus particularly suitable for handling them.
LSTM makes improvements to RNN, allowing it to capture longer-distance information. However, whether it is LSTM or RNN, there is a problem: they advance from left to right, meaning later words become more important than earlier ones. But for the task of word segmentation, this is inappropriate because every character in a sentence should have equal weight. Therefore, Bidirectional LSTM appeared. It performs one LSTM from left to right, then another LSTM from right to left, and finally combines the results of both.
Application in Word Segmentation Tasks
Attempts at combining deep learning with word segmentation were made quite early, as seen in the following articles:
In these articles, whether using simple neural networks or LSTM, their approach is the same as traditional models: they predict the label of the current character through context, where the context is a fixed window—for example, using five characters before and after plus the current character to predict the current character's label. There is nothing wrong with this approach, but it merely replaces previous methods for estimating probability, such as HMM, ME, CRF, etc., with neural networks; the entire framework remains unchanged, and it is essentially still an n-gram model. With LSTM, LSTM itself can perform sequence-to-sequence (seq2seq) output. Therefore, why not directly output the sequence of the original sentence? This way, wouldn't we truly utilize the context of the entire text? This is the attempt of this article.
LSTM can output a sequence based on the input sequence, and this sequence takes context connections into account. Thus, one can connect a softmax classifier to each output sequence to predict the probability of each label. Based on this sequence-to-sequence idea, we can directly predict the tags for the sentence.
Keras Implementation
Without further ado, hands-on practice is most important. The word vector dimension used is 128, and the sentence length is truncated to 32 (samples longer than 32 characters were discarded, which are very few; in fact, after splitting by natural delimiters like commas and periods, sentences rarely exceed 32 characters). This time, I used a 5-tag system. On top of the original 4 tags, an 'x' tag was added to represent portions shorter than 32 characters. For example, if a sentence is 20 characters long, then tags 21 through 32 are all 'x'.
Regarding the data, I used the portion provided by Microsoft Research (MSRA) from the Bakeoff 2005 corpus. The code is as follows; if anything is unclear, feel free to leave a comment.
We can use model.summary() to look at the structure of the model.
>>> model.summary()
_________________________________________________________________
Layer (type) Output Shape Param # Connected to
=======================================================
input_2 (InputLayer) (None, 32) 0
_________________________________________________________________
embedding_2 (Embedding) (None, 32, 128) 660864 input_2[0][0]
_________________________________________________________________
bidirectional_1 (Bidirectional) (None, 32, 64) 98816 embedding_2[0][0]
_________________________________________________________________
timedistributed_2 (TimeDistribute) (None, 32, 5) 325 bidirectional_1[0][0]
=======================================================
Total params: 760,005
_________________________________________________________________
How are the final model results? I don't intend to compare them with those evaluation results; it is not difficult for current models to achieve over 90% accuracy in testing. What I care about is the recognition of new words and the handling of ambiguity. Below are some test results (randomly selected):
RNN 的 意思 是 , 为了 预测 最后 的 结果 , 我 先 用 第一个 词 预测 , 当然 , 只 用 第一个 预测 的 预测 结果 肯定 不 精确 , 我 把 这个 结果 作为 特征 , 跟 第二词 一起 , 来 预测 结果 ; 接着 , 我 用 这个 新 的 预测 结果 结合 第三词 , 来 作 新 的 预测 ; 然后 重复 这个 过程 。
结婚 的 和 尚未 结婚 的
苏剑林 是 科学 空间 的 博主 。
广东省 云浮市 新兴县
魏则西 是 一 名 大学生
这 真是 不堪入目 的 环境
列夫·托尔斯泰 是 俄罗斯 一 位 著名 的 作家
保加利亚 首都 索非亚 是 全国 政治 、 经济 、 文化中心 , 位于 保加利亚 中 西部
罗斯福 是 第二次世界大战 期间 同 盟国 阵营 的 重要 领导人 之一 。 1941 年 珍珠港 事件发生 后 , 罗斯 福力 主对 日本 宣战 , 并 引进 了 价格 管制 和 配给 。 罗斯福 以 租 借 法案 使 美国 转变 为 “ 民主 国家 的 兵工厂 ” , 使 美国 成为 同 盟国 主要 的 军火 供应商 和 融资 者 , 也 使得 美国 国内 产业 大幅 扩张 , 实现 充分 就业 。 二战 后期 同 盟国 逐渐 扭转 形势 后 , 罗斯福 对 塑造 战后 世界 秩序 发挥 了 关键 作用 , 其 影响 力 在 雅尔塔 会议 及 联合国 的 成立 中 尤其 明显 。 后来 , 在 美国 协助 下 , 盟军 击败 德国 、 意大利 和 日本 。
It can be observed that the test results are very optimistic. Whether it is personal names (Chinese or foreign) or place names, the recognition effect is excellent. Regarding this model, that's all for now; I will continue to go deeper in the future.
Finally
In fact, this article provides a framework that can directly perform sequence labeling through Bidirectional LSTM to provide a complete labeling sequence. This labeling approach can be used for many tasks, such as part-of-speech tagging and entity recognition. Therefore, the seq2seq labeling approach based on Bidirectional LSTM has very broad applications and is worth studying. Even the currently popular deep learning machine translation is implemented using this type of sequence-to-sequence model.
msr_train.txt.zip