DOM Tree Numbering
By 苏剑林 | June 06, 2017
The solution mentioned previously is essentially sufficient if the crawled page has only a single effective area, such as a blog page or a news page. However, for websites with distinct hierarchical divisions, such as forums, we need further subdivision. This is because, after the aforementioned steps, while we can extract the effective text, the result is that all text is lumped together.
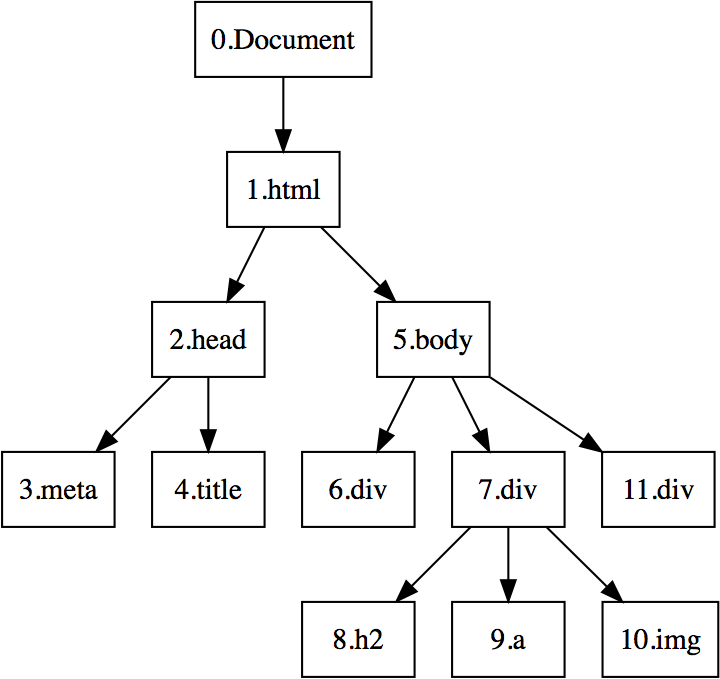
In order to further "chunk" the content, we also need to utilize the position information from the DOM tree. As shown in the DOM tree diagram in the previous article, we need to number every node and leaf, which requires a method to traverse the DOM tree. Here, we adopt a "Depth-First" approach.
Depth-First Search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking. This process continues until all nodes reachable from the source node have been discovered. If any undiscovered nodes remain, one of them is selected as a new source, and the process is repeated until all nodes have been visited.
After a depth-first search of the DOM tree from the previous article, the numbering of each node and leaf is shown in the figure below.
DOM Tree Numbering
Numbering nodes is for subsequent clustering, and we naturally hope that the difference in numbering within the same class is as small as possible. Among many HTML tags, quite a few only serve to represent emphasis, hyperlinks, etc., such as the strong tag for bolding, the em tag for italics, and so on. These tags only change the style of the content without changing its hierarchy. Therefore, when traversing these tags, the numbering can remain unchanged. This ensures that tags within the same hierarchy are more similar, ensuring the effectiveness of clustering.
The exception tags we have listed are shown in the table below:
| Tag | Meaning |
|---|---|
| p/br | Line break |
| strong/b | Bold |
| em | Italic |
| font | Font style |
| u | Underline |
| a | Hyperlink |
| img | Insert image |
| h1/h2/h3/h4/h5 | Heading markers |
For the complete list of exception tags, please refer directly to the source code.
By extracting the effective text through the previous steps and numbering it via the depth-first method described above, we obtain a sequence regarding text positions. We will find that the difference in numbering within the same module is relatively small, while the difference between different modules is relatively large. For example, the position numbers of the title, date, and content of the same article are very close, and the position numbers of the title, date, and reply content of a post on the same floor are also relatively close, as shown below. This induces us to use these position numbers to further cluster the effective text.
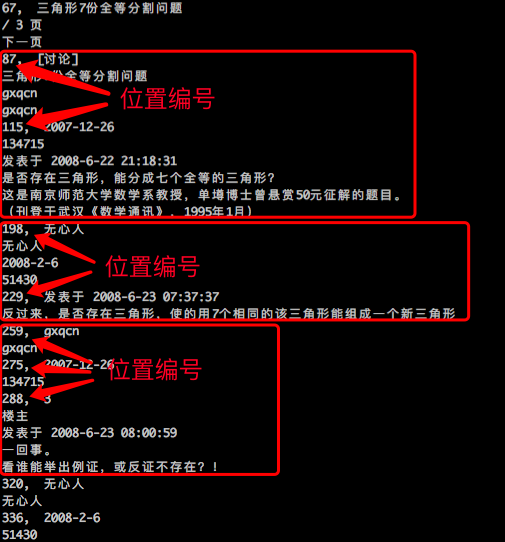
BBS floor division
To this end, we examine the differential graph of the position sequence and describe the floor boundaries of the actual situation with red dashed lines, resulting in the following figure:
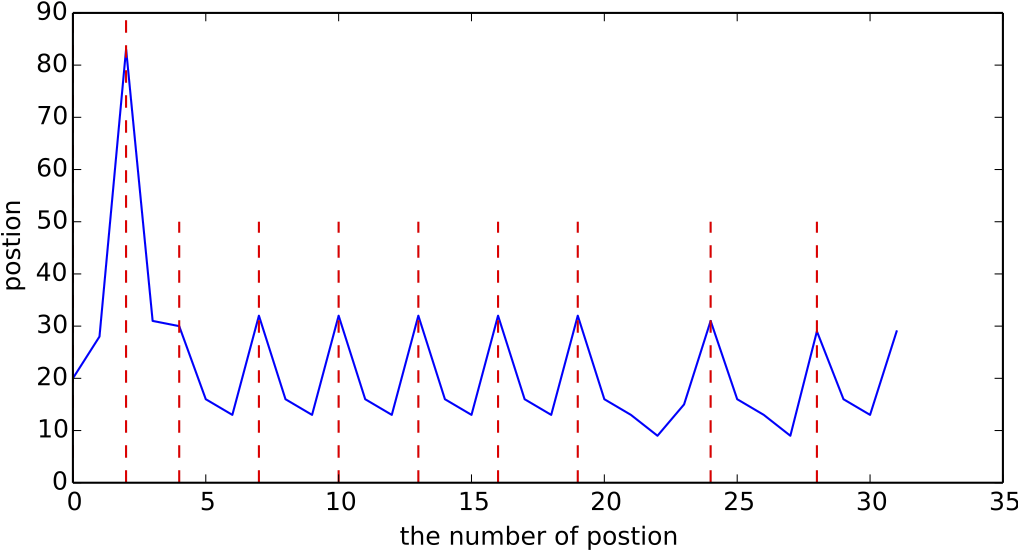
The result of taking the differential of the position numbering sequence, using the index of the differential sequence as the x-axis and the differential result as the y-axis.
The figure above shows a very obvious pattern: the boundaries of each floor are basically at the local maximums of the differential sequence. Therefore, we can use this scheme to perform segmentation-style clustering, splitting the text at local peaks. This clustering method has excellent properties, such as:
1. It can automatically determine the number of clusters, meaning we don't need to know in advance exactly how many floors there are;
2. It adapts to special cases. For example, if the second and third to last floors are wider than other floors because they contain comments within the floor (so-called "floor-within-floor"), this pattern still holds true even if the content is more extensive.
This shows that using this pattern to block text and divide different floors is quite reliable. Furthermore, this clustering can be run repeatedly to adapt to different granularity requirements. In fact, for forums, running it approximately $1 \sim 2$ times is enough to obtain the floor division.
Finally, specifically for forums, we categorize the content of each text area. To avoid complicates the crawler and ensure the efficiency of the crawler itself, the recognition methods used here are relatively simple and are purely rule-based classifications.
Title recognition is relatively simple because normal page source codes contain a <title> field, which basically contains complete title information. Therefore, we just need to extract the title directly using regular expressions.
In Chinese forums, several date formats are common:
2017-1-9 15:42
2017年 1月 9日 15:42
3小时前 (3 hours ago)
昨天 20:48 (Yesterday 20:48)
The first two date formats are easier to recognize, while the latter two are more difficult. The latter two formats mainly appear in posts published within a short period on certain forums and usually automatically revert to the first two formats after a day or two.
In this case, from the perspective of simplicity and stability, we can adopt a compromise strategy: do not recognize the dates for this part of the short-term posts on these websites and save them mixed together. From a continuous monitoring perspective, after a day or two, we will be able to recognize the dates. This neither affects the real-time nature of monitoring nor makes the program simpler and more reliable.
In fact, identifying the author (the poster) is quite difficult; we have not found an effective algorithm to complete a universal author recognition model. also, considering that the value of identifying the poster is not particularly high, we ultimately abandoned this part of the recognition work.
After identifying the time, the single text area is split into upper and lower halves by the time. We assume that one of the two halves is the main content. To identify which half is the body, we perform global statistics on both halves respectively and compare which half contains more Chinese characters. The half with more is considered the main content.
Of course, from a more rigorous perspective, one could follow the academic thinking in the previous article and use a language model to determine which part is closer to natural language, thereby identifying the main body. However, the efficiency of this scheme is low, and since we are primarily concerned with crawling Chinese content, we excluded this scheme from our experiments.