By 苏剑林 | June 7, 2017
Partial Results
Crawling results for partial websites. Figure 1 shows the crawling effect of this blog, indicating that the solution is applicable to general websites; Figure 2 and Figure 3 show the crawling effects of forums built using two open-source forum programs, indicating that open-source programs can be crawled normally; Figure 4 is the crawling effect for the famous Tianya Forum, indicating that even for forums developed internally by a company, it still achieves good results.

6-blog

6-Discuz
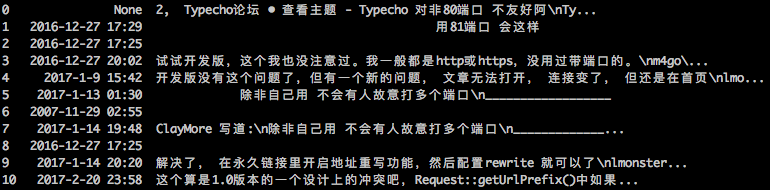
6-phpbb
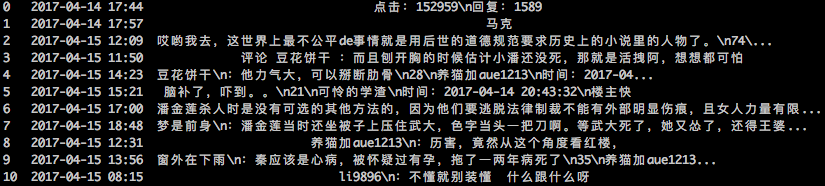
6-tianya
Room for Improvement
Overall, this is a high-efficiency, unsupervised general website crawling solution that can adapt to different websites (not limited to forums) and is suitable for large-scale enterprise deployment.
Of course, this solution also has some areas to be improved:
1. To ensure efficiency and stability, universality was sacrificed. For example, when making choices about content, it directly judges based on the proportion of Chinese characters, without using more precise language model solutions;
2. The space for further improvement is small, because the solution based on standard template comparison extracts effective text directly in a mixed manner, losing positional and hierarchical information. Although clustering can further solve this situation, there are still websites where it fails, and the room for improvement on the basis of the original method is not large;
3. Visual information is not utilized. For example, it is impossible to accurately locate usernames because we don't know what counts as a username. However, if viewed by the naked eye, it is relatively easy to judge. In other words, visual information is an important indicator; if higher precision is required, we need to utilize visual information.
Looking forward to seeing better solutions.
Code
Python 2.7 code~
General crawling framework:
Implementation for forums:
Reprinting should include this article address: https://kexue.fm/archives/4430