By 苏剑林 | September 03, 2017
Preface
Starting this year, the CCL conference (Chinese Computational Linguistics) plans to hold evaluation activities concurrently. I have been interning at a startup recently, and the company signed up for this evaluation. The implementation task ended up falling on me. This year's task is reading comprehension, titled "The First 'iFLYTEK Cup' Chinese Machine Reading Comprehension Evaluation." Although it is called reading comprehension, the task is actually quite simple—it belongs to the Cloze Test type. Specifically, a blank is dug out of a passage, and you must select a word from the context to fill in this blank. Ultimately, our model ranked 6th among single systems, with an accuracy of 73.55% on the validation set and 75.77% on the test set. You can view the leaderboard here. ("Guangzhou Flame Information Technology Co., Ltd." is the model described in this article.)
In fact, this dataset and task format were proposed by the Harbin Institute of Technology (HIT) last year, so this evaluation was jointly organized by HIT and iFLYTEK. HIT's paper from last year, "Consensus Attention-based Neural Networks for Chinese Reading Comprehension", studied another dataset with the same format but different content using common reading comprehension models (Common reading comprehension refers to finding the answer to a question from a passage; a cloze test can be considered a very small subset of general reading comprehension).
Although the evaluation organizers tended to guide us toward understanding this as a reading comprehension problem, I feel that reading comprehension itself is much more difficult. This is just a cloze test, so we can treat it as such. Therefore, this article merely adopts a language model-like approach. The advantage of this approach is that the thinking is simple and direct, the computational cost is low (it can run with a batch size of 160 on my GTX1060), and it is easy to experiment with.
Model
Returning to the model, our design is relatively simple and closely follows the idea of "selecting a word from the context to fill in the blank," as shown in the schematic diagram below.
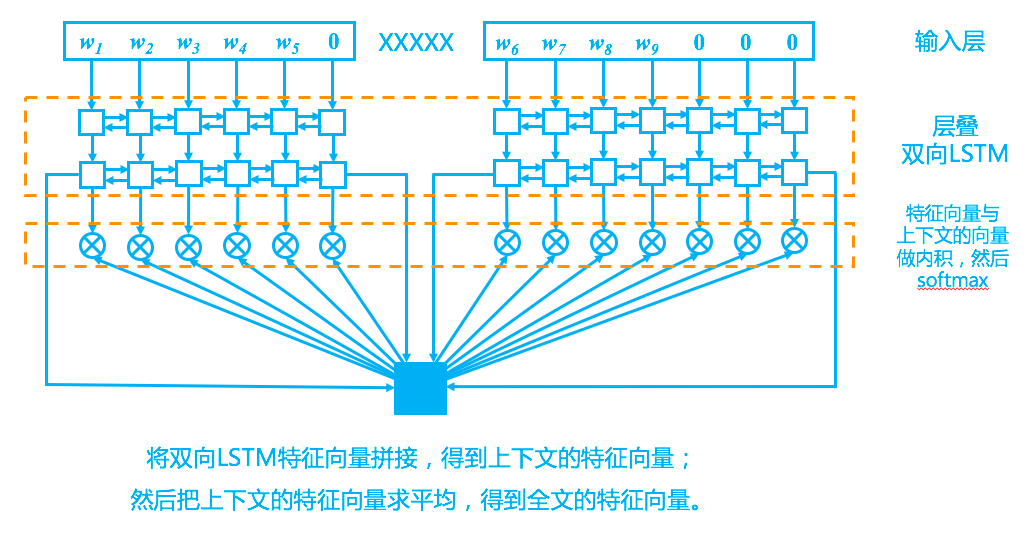
Cloze Model
Preliminary Analysis
First, it should be noted that this task involves selecting a word from the context to fill a missing position. For example:
【Passage】
1 ||| The Industry and Commerce Association reported that consumer confidence rose to 78.1 in December, significantly higher than 72 in November.
2 ||| Additionally, according to the Wall Street Journal, 2013 was the best-performing year for the US stock market since 1995.
3 ||| In this year, the wise practice for investing in the US stock market was to chase "dumb money."
4 ||| The so-called "dumb money" XXXXX , in fact, is the ordinary strategy of buying and holding US stocks.
5 ||| This strategy performed much better than the more complex investment methods used by hedge funds and other professional investors.
【Question - Cloze type】
The so-called "dumb money" XXXXX, in fact, is the ordinary strategy of buying and holding US stocks.
【Answer】
strategy
Friends familiar with Natural Language Processing (NLP) will associate this task with language modeling. In fact, the task itself is similar to a language model but perhaps even simpler. A language model predicts the next word from the previous $n$ words, requiring an iteration over all words in the vocabulary. In contrast, this cloze task only requires picking from the context, which significantly narrows the search range. Of course, the focus of the two is different: language models are concerned with probability distribution, while cloze tests are concerned with prediction accuracy.
Context Encoding
Based on experience, LSTM works best for language modeling; therefore, we also use LSTM here. To better capture global semantic information, we stacked multiple layers of bidirectional LSTMs—this is standard procedure in NLP.
First, we split the material using "XXXXX" into a prefix and a suffix. The prefix and suffix are sequentially input into the same bidirectional LSTM (calculated twice rather than concatenated once) to obtain their respective features. In other words, the prefix and suffix LSTMs share parameters. Why? Because when we read context ourselves, we use the same brain; there is no need to treat them differently. Once there is one layer of LSTM, multiple layers can be stacked. As for how many layers are suitable, it depends on the specific dataset. For this competition task, two layers showed significant improvement over a single layer, while three layers showed no improvement or even a slight decline.
Finally, to obtain the feature vector of the entire material (used for the matching below), we simply concatenate the final state vectors of the bidirectional LSTM to get the feature vectors for the prefix and suffix, and then average the two vectors to get the global feature vector.
(It is worth noting that if we switch to the dataset from the paper "Consensus Attention-based Neural Networks for Chinese Reading Comprehension"—which has the same format but content from the People's Daily—and use the same model, the number of LSTM layers needs to be 3, and the final accuracy is 0.5% higher than the best result in that paper.)
Predicting Probabilities
The next question is: how to implement "searching within the context" instead of searching through the entire vocabulary?
Recalling when we build language models, if we want to search the entire vocabulary, we build a fully connected layer where the number of nodes is the number of words in the vocabulary, and then use softmax to predict probability. We can view the fully connected layer this way: we assign a vector with the same dimension as the output feature to every word in the vocabulary, calculate the inner product, and apply softmax. That is, the pairing of features and words is achieved through the inner product. This provides a reference idea: if we make the feature output by the LSTM have the same dimension as the word vectors, and then perform an inner product between this feature and each input word vector in the context, we can then apply softmax. This achieves searching only within the context.
I initially used this approach, but the accuracy only reached 69%–70%. After analysis, it appeared that after the original word vectors go through multiple layers of LSTM encoding, they actually move far away from the original word vector space. Instead of "traveling a long distance" to pair with the input word vectors, why not pair them directly with the intermediate state vectors of the LSTM? At least within the same LSTM layer, the state vectors are relatively close (meaning they are in the same vector space), and matching should be easier.
Experiments confirmed my suspicion. With the improved model, the accuracy reached about 73%–74% on the official validation set and 75%–76% on the test set. After a further period of experimentation, there was no significant improvement, so this model was submitted.
Implementation Details
In fact, I am not very good at parameter tuning, so the parameters in the code below are not necessarily optimal. I look forward to tuning experts optimizing various parameters to yield even better results. I believe that even for the model described in this article, the results we provided were not yet optimal.
Below are some important details in the implementation of the model:
- 1. The corpus domain for this competition is fairy tales. We pre-trained Word2Vec word vectors using the training corpus and supplementary fairy tale corpus (refer here for crawling methods), which were then used as input for the LSTM.
- 2. To handle Out-of-Vocabulary (OOV) words, we generally set a padding symbol UNK (ID is 0 in the code). Since the word vectors are pre-trained with Word2Vec but UNK is not, only the word vector corresponding to UNK is allowed to be trained.
- 3. Use
bidirectional_dynamic_rnn to handle variable-length sequences.
- 4. After the inner product in the final step, a large constant ($10^{12}$ in the code) must be subtracted from the inner products at padding positions before applying softmax and calling the
softmax_cross_entropy_with_logits loss function. The reason is simple: the softmax of the inner product is the probability. To make the probability at padding positions zero, the corresponding inner product must be a very small negative number.
- 5. If the target word appears multiple times in the context, the probability is spread across every occurrence. That is, the cross-entropy target is not necessarily in one-hot format. During final prediction, the probabilities of repeated words are summed up before sorting for the maximum.
Code
Dataset
Dataset download: https://github.com/ymcui/cmrc2017
The following code can also be viewed on my Github: https://github.com/bojone/CCL_CMRC2017
Training Script
#! -*- coding:utf-8 -*-
# Experimental environment: tensorflow 1.2
import codecs
import re
import os
import numpy as np
def split_data(text):
words = re.split('[ \n]+', text)
idx = words.index('XXXXX')
return words[:idx], words[idx+1:]
print u'Reading training corpus...'
# ... (rest of the script)