By 苏剑林 | June 29, 2019
In the previous article "When Bert Meets Keras: This Might Be the Simplest Way to Open Bert," we introduced three NLP examples based on fine-tuning Bert, experiencing the power of Bert and the convenience of Keras. In this article, we add another example: an NL2SQL model based on Bert.
NL2SQL stands for Natural Language to SQL, which means converting natural language into SQL statements. It has been a subject of much research in recent years and is considered a practical task in the field of artificial intelligence. The opportunity for me to build this model was the first "Chinese NL2SQL Challenge" hosted by our company:
The first Chinese NL2SQL Challenge uses table data from the financial and general fields as data sources, providing natural language and SQL statement matching pairs annotated on this basis. It is hoped that contestants can use the data to train a model that can accurately convert natural language to SQL.
This NL2SQL competition is a relatively large NLP event this year, with significant manpower and resources invested in promotion and a generous prize pool. The only issue is that NL2SQL itself is a somewhat niche research field, so it might not be extremely popular. To lower the entry barrier, the organizers released a Baseline written in PyTorch.
With the mindset that "there shouldn't be a lack of a Keras version for the Baseline," I took some time to work on this competition using Keras. To simplify the model and improve results, I also loaded the pre-trained Bert model, which resulted in this article.
Data Example
Each data sample is as follows:
{
"table_id": "a1b2c3d4", # ID of the corresponding table
"question": "The volume ratio of the new Shimao Mao Yue Mansion development is greater than 1, what is its average area per unit?", # Natural language question
"sql":{ # True SQL
"sel": [7], # Columns selected by the SQL
"agg": [0], # Aggregation function corresponding to the selected column, '0' represents none
"cond_conn_op": 0, # Relationship between conditions
"conds": [
[1, 2, "Shimao Mao Yue Mansion"], # Condition column, condition type, condition value, col_1 == "Shimao Mao Yue Mansion"
[6, 0, "1"]
]
}
}
# The condition operators, aggregation operators, and connection operators are as follows:
op_sql_dict = {0:">", 1:"<", 2:"==", 3:"!="}
agg_sql_dict = {0:"", 1:"AVG", 2:"MAX", 3:"MIN", 4:"COUNT", 5:"SUM"}
conn_sql_dict = {0:"", 1:"and", 2:"or"}
Each sample corresponds to a data table containing all column names of that table and the corresponding data records. In principle, the generated SQL statements should be executable on the corresponding data table and return valid results.
It can be seen that although it is called NL2SQL, the organizers have actually formatted the SQL statements very clearly. In this way, the task can be greatly simplified. For example, the sel field is actually a multi-label classification model, but the categories may change at any time because the categories here actually correspond to the columns of the data table. Since the data tables and meanings for each sample are different, we must dynamically encode a category vector based on the table's column names. As for agg, there is a one-to-one correspondence with sel, and the categories are fixed. The cond_conn_op is a single-label classification problem.
The final conds is relatively more complex. it requires a combination of sequence labeling and classification because it needs to simultaneously determine which column is the condition, the operation relationship of the condition, and the value corresponding to the condition. It should be noted that the condition value is not always a fragment of the question; it may be a formatted result. For example, if the question contains "year 16", the condition value might be the formatted "2016". however, since the organizers guarantee that the generated SQL can be executed on the corresponding data table and yield valid results, if the condition operator is "==", then the condition value will definitely appear in the values of the corresponding column in the data table. For example, in the sample above, the first column of the data table must contain the value "Shimao Mao Yue Mansion", and through this information, we can also calibrate the prediction results.
Model Structure
Before formally looking at this model, readers might want to think for a moment and consider how they would do it. Only after thinking will you understand where the difficulties lie, and only then can you understand the key points of some processing techniques in this model.
The model schematic diagram in this article is as follows:
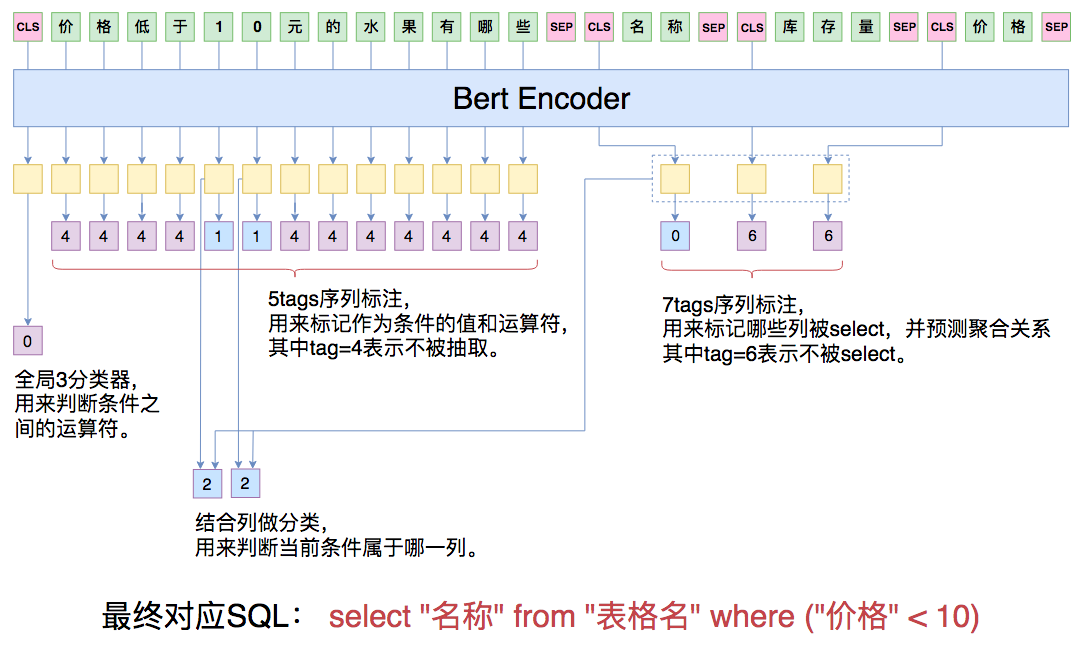
Schematic diagram of the NL2SQL model in this article. It mainly includes 4 different classifiers: sequence labeler, etc.
For a SQL statement, the most basic part is to decide which columns will be select-ed. Since the meaning of the columns in each table is different, we concatenate the question sentence with all the table headers of the data table and input them together into the Bert model for real-time encoding. Each table header is also treated as a sentence, enclosed by [CLS]***[SEP]. After Bert, we obtain a series of encoding vectors, and then we see how to use these vectors.
We can consider the vector corresponding to the first [CLS] as the sentence vector for the entire question, and we use it to predict the connection operator for conds. The vectors corresponding to each subsequent [CLS] are considered the encoding vectors for each table header. We extract them to predict whether the column represented by that table header should be select-ed. Note that there is a trick in the prediction here: besides predicting sel, we also need to predict the corresponding agg. There are a total of 6 categories for agg, representing different operations. Therefore, we simply add an additional category, the 7th category, representing that this column is not select-ed. In this way, each column corresponds to a 7-class classification problem. If it is classified into the first 6 categories, it means the column is select-ed and the agg is predicted at the same time; if it falls into the 7th category, it means the column is not select-ed.
Now we are left with the more complex conds, such as where col_1 == value_1. We need to find col_1, value_1, and the operator ==. The prediction of conds is divided into two steps: the first step predicts the condition values, and the second step predicts the condition columns. Predicting the condition value is actually a sequence labeling problem. There are 4 operators corresponding to the condition value; we also add an additional category to make it 5, where the 5th category represents that the current character is not labeled, otherwise it is labeled. In this way, we can predict the condition value and the operator. The remaining part is to predict the column corresponding to the condition value. We calculate the similarity between the character vectors of the labeled value and the vector of each table header one by one, and then apply softmax. My method for calculating similarity here is the simplest: directly concatenate the character vector and the table header vector, then pass it through a fully connected layer followed by a Dense(1). The reason for making it so simple is, first, because the main purpose of this article is to provide a basically feasible demo rather than a perfect program, leaving some room for improvement for the reader; second, because making it more complex could easily lead to insufficient video memory and OOM (Out of Memory).
By the way, the model in this article was "constructed independently" based on the competition task. If readers want to discuss mainstream NL2SQL models with me, I may be of no help. Please understand.
Experimental Results
The code for the model in this article is located at:
https://github.com/bojone/bert_in_keras/blob/master/nl2sql_baseline.py
Note: If you run this code and get an error, you may need to modify Keras's backend/tensorflow_backend.py. In the sparse_categorical_crossentropy function, change the original line:
logits = tf.reshape(output, [-1, int(output_shape[-1])])
to
logits = tf.reshape(output, [-1, tf.shape(output)[-1]])
I have submitted this fix to the official repository, and it has been approved (please see here). This feature should be automatically included in future versions.
Again, as long as you have carefully observed the competition data and thought about this task independently, the model introduced in this article is actually very easy to understand. The fact that a simple model can achieve good results is due to Bert's powerful semantic encoding capability. On the offline valid set, the SQL exact match rate generated by the model in this article is about 58%. The official evaluation metric is (Exact Match Rate + Execution Match Rate) / 2, which means you might write a SQL statement different from the labeled answer, but if the execution result is consistent, it counts as half-correct.
As a result, the final score will definitely be higher than 58%, and I estimate it to be around 65%. Looking at the current leaderboard, 65% would place in the top few ranks (the top player is currently at 70%). Since company employees are not allowed to participate in the rankings, I haven't participated in the evaluation and don't know the online submission score. Interested contestants can submit their own tests.
Additionally, to run this script, it's best to have a 1080ti or higher graphics card. If you don't have that much memory, you can try reducing maxlen and batch size. Also, there are currently two Chinese pre-trained Bert weights available: the Official version and the Harbin Institute of Technology (HIT) version. The final results of the two are similar, but the HIT version converges faster.
Looking at the entire model, the most difficult part of the implementation is the careful consideration of various masks. In the script mentioned above, xm, hm, cm are three mask variables used to remove the effects brought by the padding part during the training process. Note that masks are not unique to Keras; whether you use TensorFlow or PyTorch, theoretically, you must handle masks carefully. If readers really cannot understand the mask part, you are welcome to leave a comment to ask and discuss, but before asking, please answer the following question:
What does the sequence look like before the mask? Which positions in the sequence changed after the mask? How did they change?
Answering this question proves "you already understand what calculations the program performed, you just don't understand why it calculated that way." If you don't even understand the calculation itself, I'm afraid it will be very difficult for us to communicate (you should at least be able to tell which part changed...). You'd better learn Keras or TensorFlow properly before playing with this; you can't expect to succeed in one step.
Post-processing
For the model, implementation difficulty lies in the masks. However, if you look at the entire script, the largest proportion of code is actually for data reading, pre-processing, and result post-processing. Building the model itself takes only about twenty lines (once again marvelling at the simplicity of Keras and the power of Bert).
As mentioned, the condition value does not necessarily appear in the question. How do we extract the condition value using sequence labeling on the question?
My method is that if the condition value does not appear in the question, I segment the question and find all 1-grams, 2-grams, and 3-grams of the question. Then, I find the n-gram closest to the condition value as the labeled fragment. During prediction, if an n-gram is found as the condition value and the operator is "==", we check if this n-gram has appeared in the database. If it has, it's kept directly; if not, we find the closest value in the database.
The corresponding processes are all reflected in the code; feel free to read carefully.
Summary
Everyone is welcome to play~

First Chinese NL2SQL Challenge
https://tianchi.aliyun.com/markets/tianchi/zhuiyi_cn
I wish everyone good results!