By 苏剑林 | December 14, 2019
From the article "From Language Models to Seq2Seq: Transformer as a Play, Relying Entirely on Masking", we know that as long as it is paired with the appropriate Attention Mask, Bert (or other Transformer models) can be used for unconditional generation (Language Model) and sequence translation (Seq2Seq) tasks.
But what if it is conditional generation? For example, controlling the category of text to generate text randomly based on a category, which is a Conditional Language Model; or another example, passing in an image to generate a related text description, which is Image Captioning.
Related Work
The August paper "Encoder-Agnostic Adaptation for Conditional Language Generation" systematically analyzes several schemes for using pre-trained models for conditional generation; a September paper "CTRL: A Conditional Transformer Language Model for Controllable Generation" provides a model pre-trained based on conditional generation, but this is essentially a language model like GPT that can only take text input as a condition; and the recent paper "Plug and Play Language Models: a Simple Approach to Controlled Text Generation" transforms $p(x|y)$ into $p(x)p(y|x)$ to explore conditional generation based on pre-trained models.
However, these classic works are not what this article is about. This article focuses on a scenario where a fixed-length vector is used as the condition for text generation, and the method is Conditional Layer Normalization—integrating the condition into the \(\beta\) and \(\gamma\) of Layer Normalization.
Idea Details
The idea of Conditional Layer Normalization originates from the popular Conditional GAN approach in image processing—Conditional Batch Normalization (Conditional BN). Related content can be found in "An Overview of GAN Architecture Development: From DCGAN to SELF-MOD". Conditional BN also has a variant called AdaIN (Adaptive Instance Normalization). Both Conditional BN and AdaIN turn the \(\beta\) and \(\gamma\) in existing Normalization methods into functions of the input condition, thereby allowing the condition to control the generative behavior.
In Transformer models like Bert, the main Normalization method is Layer Normalization. Therefore, it is natural to think of turning the corresponding \(\beta\) and \(\gamma\) into functions of the input condition to control the generative behavior of the Transformer model. This is the core logic of Conditional Layer Normalization. (However, as of now, I haven't seen other work appearing with the same approach, so this can be considered a bit of "reinventing the wheel" on my part.)
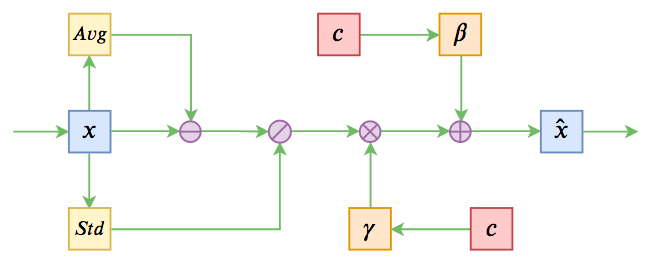
Conditional Normalization Diagram
For models that have already been pre-trained, there are already ready-made, unconditional \(\beta\) and \(\gamma\), which are both fixed-length vectors. We can use two different transformation matrices to transform the input condition into the same dimension as \(\beta\) and \(\gamma\), and then add the two transformation results separately to \(\beta\) and \(\gamma\). To prevent disturbing the original pre-trained weights, the two transformation matrices can be initialized to all zeros (single-layer neural networks can use zero initialization; only continuous multi-layer neural networks should avoid zero initialization). In this way, in the initial state, the model remains consistent with the original pre-trained model.
Code Implementation
Intuitively, this type of fine-tuning for text generation should use autoregressive pre-trained models like GPT to improve effectiveness. But in fact, as shown in the previous article "From Language Models to Seq2Seq: Transformer as a Play, Relying Entirely on Masking", even if you load Bert's pre-trained weights to perform generation tasks, performance remains good. Therefore, regardless of the type of Transformer-based pre-trained model, it can be considered for fine-tuning as a text generation model. This article uses the pre-trained BERT as the base model for experiments.
As for the code, the Conditional Layer Normalization technique described in this article has already been integrated into bert4keras, which I developed. Now, the base function build_transformer_model has been updated with the following parameters:
1. layer_norm_cond: If this parameter is not None, it means it is a tensor with shape=[batch_size, cond_size], used as the condition for Layer Normalization;
2. layer_norm_cond_size: If this parameter is not None and layer_norm_cond is None, it means it is an integer, and an input layer with shape=[batch_size, layer_norm_cond_size] will be automatically constructed as the condition for Layer Normalization;
3. layer_norm_cond_hidden_size: If this parameter is not None, it means it is an integer, used to project the input condition into a lower-dimensional space first. This is because the input condition might have a very high dimension; projecting it directly to hidden_size (e.g., 768) might involve too many parameters, so it can be projected to a lower dimension first and then up-sampled;
4. layer_norm_cond_hidden_act: The activation function used when projecting to the lower-dimensional space. If it is None, no activation function is applied (linear activation);
5. additional_input_layers: Additional input layers. If a tensor is passed externally as a condition, all input layers that the condition tensor depends on need to be added to build the final model.
Experimental Results
No matter how much I introduce it, it's better to look at examples. I conducted two experiments to verify the effectiveness of Conditional Layer Normalization. One is controlling text generation via sentiment polarity (the inverse of sentiment classification), which uses class Embeddings as the Layer Normalization condition; the other is Image Captioning, where a fixed-length vector encoded from an image using a pre-trained Imagenet model is used as the Layer Normalization condition.
These two codes are located in task_conditional_language_model.py and task_image_caption.py respectively.
Sentiment Text Generation
The sentiment text generation uses the sentiment classification corpus I collected and organized previously, simply reversing the input text and labels. Finally, sampling the output randomly according to probabilities allows for the generation of different texts.
Partial output:
Positive samples:
['The appearance is stylish, beautiful, and the cost-performance ratio is high.', 'Beautiful appearance, balanced configuration, quite satisfied, high cost-performance ratio, beautiful appearance, high performance.', 'I saw this book when I was in university, so I have been buying it. The author of the book is Lin Jinglei, who wrote about the psychological journey of a child’s growth in her own voice, allowing me to see the different aspects of their growth and the different realms of their growth process. I really appreciate it!', 'I think this is a book that can tell readers what is bad, rather than teaching you how to speak or telling me what is wrong. Here I recommend "I Want to Tell a Story". This book is one of my favorites, I think there are many reasons for it, but I believe in myself. If you get some improvement from it, or you have already made a wise decision.', 'Our family of five stayed in a standard room, a king room, the king bed was very comfortable; and we booked two sets of king rooms on Ctrip, the price of this hotel is quite reasonable; but the soundproofing of the room is not ideal, there is a bit of noise; the subway at the hotel entrance is under construction, which is inconvenient; but the taxis at the hotel entrance don't know whose they are, taking a taxi is not very convenient; outside the hotel...']
Negative samples:
['I don't know if it's because the battery is not very good, it's not that I don't like it.', 'I bought it after reading the reviews. It turns out it's not that cheap, and the price is not cheap either.', '1. The shell is not easy to leave fingerprints on, but not easy to wash 2. The screen is a bit old and ringtones cannot be downloaded', 'I ordered "A Story of Lala's Promotion" on July 6th and paid via bank transfer. Why has it been more than two weeks and the order hasn't arrived? Is the delivery time too fast? Maybe it just passed by like that?', 'I read this book online first, then I read it again. I feel like the author's writing is really terrible, especially when writing his blog, it feels very awkward and unprofessional, especially the little boy who regulates emotions when he writes about stocks, it's just self-righteous, it's simply a manifestation of being self-righteous!']
Image Caption
The Image Captioning uses the COCO dataset as an example, as the image scenes in this dataset are quite rich. In addition, challenger.ai held an Image Chinese Description Generation Competition in 2017, which also included a good dataset (readers can find ways to collect it themselves), though the image scenes are relatively monotonous.
Partial output:

Model prediction: a baseball game in progress with the batter up to plate.

Model prediction: a train that is sitting on the tracks.
image_id: COCO_val2014_000000524611.jpg
url: http://images.cocodataset.org/val2014/COCO_val2014_000000524611.jpg
predict: a train that is sitting on the tracks.
references: [u'A train carrying chemical tanks traveling past a water tower.', u'Dual train tracks with a train on one of them and a water tower in the background.', u'a train some trees and a water tower ', u'Train on tracks with water tower for Davis Junction in the rear.', u'A train on a train track going through a bunch of trees.']
image_id: COCO_val2014_000000202923.jpg
url: http://images.cocodataset.org/val2014/COCO_val2014_000000202923.jpg
predict: a baseball game in progress with the batter up to plate.
references: [u'Batter, catcher, and umpire anticipating the next pitch.', u'A baseball player holding a baseball bat in the game.', u'A baseball player stands ready at the plate.', u'Baseball players on the field ready for the pitch.', u'A view from behind a mesh fence of a baseball game.']
Conclusion
This article proposes the idea of using Conditional Layer Normalization to integrate external conditions into pre-trained models. Its direct application is conditional text generation, but it is not limited to generative models; it can also be used in classification models and other scenarios (external conditions might be information from other modalities to assist classification). Finally, code implementation based on bert4keras and two examples are provided.