Schematic diagram of the model in this article
By 苏剑林 | March 05, 2021
Recently, I decided to join the fun and participate in the "Xiao Bu Assistant Dialogue Short-Text Semantic Matching" track of the Global AI Technology Innovation Competition. The task is a standard short-text sentence pair binary classification task. In this era where various pre-trained Transformers are "running wild," this task doesn't pose much of a special challenge. However, what makes it interesting is that the data for this competition is anonymized—meaning every character has been mapped to a numeric ID, so we cannot access the original text.
Under these circumstances, can we still use pre-trained models like BERT? Certainly, they can be used, but it requires some techniques, and you might need to perform further pre-training. This article shares a baseline that combines classification, pre-training, and semi-supervised learning, which can be applied to anonymized data tasks.
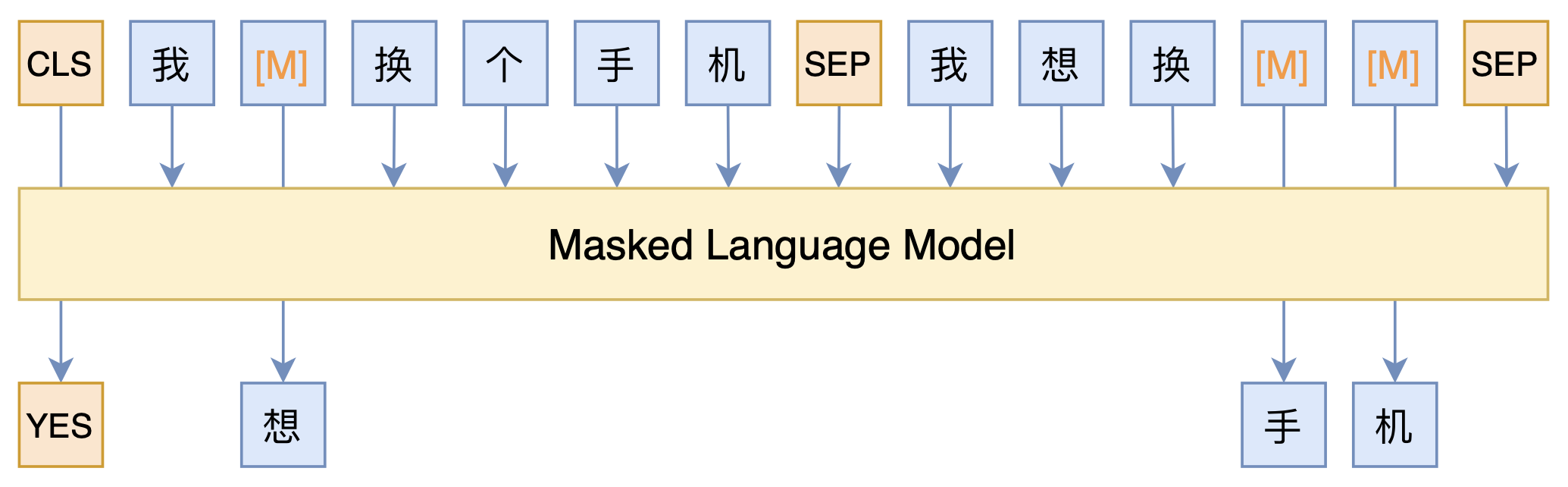
The core idea of the entire model is actually a variant of PET (Pattern-Exploiting Training) introduced in the previous article "Is GPT3 Necessary? No, BERT's MLM Model Can Also Do Few-Shot Learning". It uses an MLM (Masked Language Model) model to accomplish everything, as shown in the diagram below:
Schematic diagram of the model in this article
As can be seen, the entire model is just an MLM model. Specifically, we added two tags, $[YES]$ and $[NO]$, to the vocabulary to represent the similarity between sentences. We use the output vector corresponding to $[CLS]$ to predict the label of the sentence pair ($[YES]$ or $[NO]$). The corpus is constructed by conventionally concatenating sentence pairs, randomly masking some tokens in both sentences, and then predicting those tokens at the corresponding output positions.
In this way, we simultaneously perform the sentence pair classification task (via the prediction results of $[CLS]$) and the MLM pre-training task (for other masked tokens). Moreover, unlabeled samples (such as the test set) can also be thrown in for training, as long as we don't predict the $[CLS]$ for them. Thus, through the MLM model, we integrate classification, pre-training, and semi-supervised learning together.
Can BERT still be used with anonymized data? Of course. For BERT, anonymized data only means the Embedding layer is different; the other layers are still very valuable. Therefore, reusing BERT primarily involves re-aligning the Embedding layer through pre-training.
During this process, initialization is crucial. First, we take out special tokens like $[UNK]$, $[CLS]$, and $[SEP]$ from BERT's Embedding layer; these parts remain unchanged. Then, we separately count the character frequencies of the encrypted (anonymized) data and the plain-text data. Plain-text data refers to any open-source general corpus, not necessarily the actual plain-text corresponding to the encrypted data. Next, we align the plain-text vocabulary with the encrypted vocabulary based on frequency. In this way, we can use the plain-text character to extract the corresponding BERT Embedding as the initialization for the anonymized character.
Simply put, I use the BERT Embedding of the most frequent plain-text character to initialize the most frequent anonymized character, and so on, to perform a basic vocabulary alignment. My personal comparative experiments show that this operation can significantly speed up the model's convergence.
Having said this, the model introduction is basically complete. Using this operation with the BERT-base version, the score on the leaderboard is 0.866, while the offline score is already 0.952 (single model, no K-fold ensemble; everyone seems to have a large gap between online and offline). Here I share my bert4keras implementation:
Github Address: https://github.com/bojone/oppo-text-match
Regarding the character frequency of the plain-text data, I have already pre-calculated a copy and synchronized it to Github; you can use it directly. It is recommended to train for 100 epochs, which takes about 6 hours on a 3090.
By the way, if you want to use the BERT-large version, I do not recommend using the RoBERTa-wwm-ext-large released by the Harbin Institute of Technology. The reason has already been mentioned in "Is GPT3 Necessary? No, BERT's MLM Model Can Also Do Few-Shot Learning": for some reason, that version has randomly initialized weights for the MLM part, and we need to use the MLM weights. If you need a Large version, I recommend using the BERT Large released by Tencent UER.
There isn't much else to say; I've just shared a simple baseline for the competition and put together a blog post along the way. I hope it is helpful to everyone~