By 苏剑林 | September 06, 2016
During the summer vacation, I participated in the Core Entity Recognition Competition jointly organized by Baidu and Xi'an Jiaotong University. The final results were quite good, so I'm recording it here. The performance of the model is not the absolute best, but it excels at being "end-to-end" and has strong transferability, which I believe will be of reference value to everyone.
The theme of the competition is "Core Entity Recognition," which actually involves two tasks: Core Recognition + Entity Recognition. Although these two tasks are related, in traditional natural language processing programs, they are generally handled separately. This time, they need to be combined. If we only look at "Core Recognition," it is a traditional keyword extraction task. However, the difference is that traditional purely statistics-based approaches (such as TF-IDF extraction) are not feasible because a core entity in a single sentence might only appear once. In such cases, statistical estimation is unreliable, and it is better to understand it from a semantic perspective. I initially started with "Core Recognition" using a method similar to a QA system:
1. Segment the sentence into words, then use Word2Vec to train word vectors;
2. Use a Convolutional Neural Network (in this type of extraction problem, CNNs often perform better than RNNs) to perform convolution and obtain an output with the same dimension as the word vector;
3. The loss function is the cosine similarity between the output vector and the vector of the core word in the training sample.
Thus, to find the core words of a sentence, I only needed to calculate an output vector for each sentence and then compare its cosine similarity with the vector of each word in the sentence, sorting them in descending order. The obvious advantage of this method is its fast processing speed. In the end, I used this model to achieve an accuracy of 0.35 on the public evaluation set. Later, I felt it was difficult to improve and abandoned this approach.
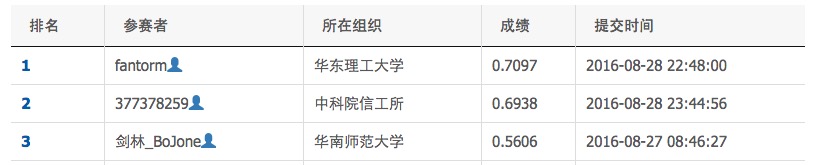
Worshiping the 0.7 masters
Why did I give up? In fact, while this approach performed well in the "Core Recognition" part, its fatal flaw was its dependence on word segmentation performance. Segmentation systems often split core entities composed of long words. For example, "Zhu Family Garden" (朱家花园) might be split into "Zhu Family/Garden" (朱家/花园). After segmenting, it becomes much more difficult to integrate them back. Consequently, I referred to the article "【Chinese Word Segmentation Series】 4. seq2seq Character Labeling based on Bidirectional LSTM" and adopted the sequence labeling approach, as it does not clearly depend on segmentation results. Ultimately, I achieved 0.56 accuracy using this method.
The main steps were:
1. Segment the sentences and train word vectors with Word2Vec;
2. Convert the output into a 5-tag labeling problem: b (beginning of core entity), m (middle of core entity), e (end of core entity), s (single word as core entity), x (non-core entity part);
3. Use a dual-layer Bidirectional LSTM for prediction and the Viterbi algorithm for labeling.
Finally, it is worth mentioning that according to this approach, one could even perform core entity recognition without prior word segmentation. However, generally speaking, segmented results are better, and segmentation helps reduce sentence length (a 100-character sentence becomes a 50-word sentence after segmentation), which is beneficial for reducing model parameters. Here, we only need a simple segmentation system without needing its built-in new word discovery features.
Transfer Learning
Before using this approach, I was very uncertain about its final effectiveness. The main reason was: Baidu provided 12,000 training samples, but there were 200,000 test samples. This ratio is so disparate that the performance seemed unlikely to be good. Furthermore, there are 5 tags, and compared to the 'x' tag, the numbers for the other four tags are very small. With only 12,000 training samples, there seemed to be a serious issue of insufficient data.
Of course, practice is the sole criterion for testing truth. The first test of this approach reached an accuracy of 0.42, which was much higher than the CNN approach I had meticulously tuned for over half a month. So I continued with this path. Before proceeding, I analyzed why this approach worked well. I believe the main reasons are two: one is "Transfer Learning," and the other is LSTM's powerful semantic capturing ability.
Traditional data mining training models are purely built on the training set. However, we cannot guarantee that the training set and the test set are consistent; or more accurately, it is hard to assume they share the same distribution. Consequently, even if a model trains very well, its test performance may be a mess. This is not necessarily caused by overfitting; it is caused by the inconsistency between the training and test sets.
One way to solve (or alleviate) this problem is "Transfer Learning." Transfer learning is now a comprehensive modeling strategy and will not be detailed here in full. Generally, there are two schemes:
1. Transfer learning before modeling: that is, the training set and testing set can be put together to learn the features used for modeling. The features obtained this way already contain information about the testing set;
2. Transfer learning after modeling: if the test result is reasonably good, for example, 0.5 accuracy, and you want to improve it, you can take the test set along with its prediction results as training samples and retrain the model together with the original training samples.
People might be confused about the second point: aren't the prediction results for the test set incorrect in many cases? Can inputting incorrect results improve accuracy? Tolstoy said, "All happy families are alike; each unhappy family is unhappy in its own way." Applying it here, I would say, "All correct answers are the same, while wrong answers are incorrect in their own special ways." That is to say, if the second type of training is performed, the effect of correct answers in the test set will accumulate because they all come from the same correct patterns. However, wrong answers have various wrong patterns. If the model parameters are limited and overfitting is avoided, the model will smooth out these wrong patterns and thus tend toward the correct answers. Of course, whether this understanding is accurate is for the readers to judge. Additionally, if new prediction results are obtained, one can take only the parts where two predictions were identical as training samples, making the proportion of correct answers even higher.
In this competition, transfer learning was reflected in:
1. Training Word2Vec using both training and test corpora, allowing word vectors to capture the semantics of the test corpus;
2. Training the model with training data;
3. After obtaining the model, predict the test data and use the prediction results along with the training data to train a new model;
4. Predict with the new model; the performance will improve;
5. Compare the results of two predictions. If they are identical, it indicates the prediction is very likely correct. Use this "likely correct" portion of test results to train the model;
6. Predict with the updated model;
7. If you wish, you can repeat steps 4, 5, and 6.
Bidirectional LSTM
Main model structure:
# (Original code snippet was here)
I used a dual-layer Bidirectional LSTM (I tried a single layer, but adding an extra layer performed better), preserved the output of the LSTM at each step, and applied a softmax to each output. The entire process is basically like a word segmentation system.
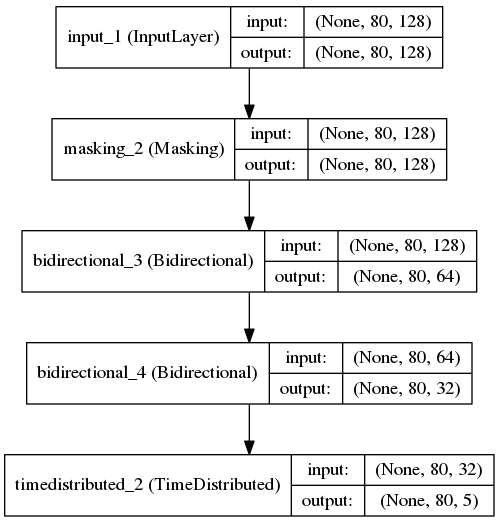
model
Of course, the quality of this model also largely depends on the quality of the word vectors. After multiple adjustments, I found the following word vector parameters to be basically optimal:
# (Original code snippet was here)
That is, skip-gram performs better than CBOW, negative sampling mode is better than hierarchical softmax, the number of negative samples should be moderate, and the window size should be moderate. Of course, this so-called "optimal" is based on my own "intuition" after manual tuning. Everyone is welcome to conduct more tests.
About the Competition
I actually noticed this competition by Baidu and XJTU last year, but I was at a novice level then and couldn't handle such a difficult task. I tried it this year and felt I gained a lot.
Firstly, the competition is held by Baidu, which in itself is very attractive. Usually, it feels like gaining Baidu's recognition is a great accomplishment, so I look forward to such competitions (I hope to have time to participate) and wish Baidu's competitions go better and better (standard formalities~). Secondly, through this process, I gained a deeper understanding of language model examples, building and using deep networks, such as how CNNs are used for language tasks, which language tasks they can be applied to, and the preliminary use of seq2seq.
Coincidentally, this was an NLP task, and the last Teddy Cup was an image task. Adding the two together, I have gone through the basic tasks of both NLP and Computer Vision. I now feel quite confident about handling these tasks; it feels very grounding.
Complete Code
Training set link: https://pan.baidu.com/s/1i457nkL Password: stkp
Description File
Core Entity Recognition based on Transfer Learning and Bidirectional LSTM
==============================================================
General Steps (corresponding in train_and_predict.py):
==============================================================
1. Segment both training and test corpora; currently using jieba;
2. Convert to a 5-tag labeling problem and construct training labels;
3. Train the Word2Vec model with both sets of corpora;
4. Train the labeling model using a dual-layer Bidirectional LSTM based on seq2seq ideas;
5. Predict with the model; accuracy will fluctuate roughly between 0.46 and 0.52;
6. Treat prediction results as labeled data and retrain the model together with training data;
7. Predict with the new model; accuracy will fluctuate between 0.5 and 0.55;
8. Compare two prediction results, take the intersection as labeled data, and retrain the model with training data;
9. Predict with the new model; accuracy stays roughly between 0.53 and 0.56.
==============================================================
Compilation Environment:
==============================================================
Hardware environment:
1. 96G memory (actually about 10G is used)
2. GTX960 graphics card (GPU accelerated training)
Software environment:
1. CentOS 7
2. Python 2.7 (all below are Python third-party libraries)
3. Jieba
4. Numpy
5. SciPy
6. Pandas
7. Keras (Official GitHub version)
8. Gensim
9. H5PY
10. tqdm
==============================================================
File Usage Instructions:
==============================================================
train_and_predict.py
Contains the entire process from training to prediction. As long as the "unopened verification data" format is the same as the "open test data" opendata_20w, it can be put in the same directory as train_and_predict.py, then run:
python train_and_predict.py
This will complete the whole process and generate a series of files:
--------------------------------------------------------------
word2vec_words_final.model, the Word2Vec model
words_seq2seq_final_1.model, the first dual-layer Bi-LSTM model
--- result1.txt, the first prediction results
--- result1.zip, compressed package of the first results
words_seq2seq_final_2.model, model after the first transfer learning
--- result2.txt, second prediction results
--- result2.zip, compressed second results
words_seq2seq_final_3.model, model after the second transfer learning
--- result3.txt, third prediction results
--- result3.zip, compressed third results
words_seq2seq_final_4.model, model after the third transfer learning
--- result4.txt, fourth prediction results
--- result4.zip, compressed fourth results
words_seq2seq_final_5.model, model after the fourth transfer learning
--- result5.txt, fifth prediction results
--- result5.zip, compressed fifth results
---------------------------------------------------------------
==============================================================
Logic Description:
==============================================================
Transfer learning is reflected in:
1. Training Word2Vec with both training and test corpora allows word vectors to capture the semantics of test items;
2. Training the model with training data;
3. After obtaining the model, predict the test data and use results alongside training data for a new model;
4. Predict with the new model to improve accuracy;
5. Compare predictions; identical results are likely correct and are used to train the model;
6. Predict with updated models;
7. Repeat steps 4, 5, 6 as desired.
Bi-LSTM logic:
1. Segment words;
2. Convert to 5-tag problem (0: non-entity, 1: single-word entity, 2: start word of multi-word entity, 3: middle of multi-word entity, 4: end of multi-word entity);
3. Directly output predicted tag sequences for input sentences via Bi-LSTM;
4. Use Viterbi algorithm to finalize results;
5. Use Bi-LSTM because standard LSTMs suffer from the disadvantage of later words being more "important" than earlier ones.
train_and_predict.py (Code not organized, for test reference only)
# (Original code snippet was here)
If you found this article helpful, you are welcome to share or donate. Donations are not for profit, but to know how many readers are genuinely interested in Scientific Spaces. Of course, if you ignore it, it will not affect your reading. Welcome and thank you!