By 苏剑林 | March 23, 2021
In the previous article, we provided a detailed derivation and understanding of the original Sinusoidal position encoding. The general feeling is that Sinusoidal position encoding is an "absolute position encoding that wants to be a relative position encoding." Generally speaking, absolute position encoding has the advantages of simple implementation and fast calculation, while relative position encoding directly reflects relative position signals, which aligns with our intuitive understanding and often yields better actual performance. It follows that if one can implement relative position encoding via an absolute position encoding method, it would be a "best of both worlds" design. Sinusoidal position encoding vaguely achieves this, but not well enough.
This article will introduce our self-developed Rotary Transformer (RoFormer) model. Its main modification is the application of "Rotary Position Embedding (RoPE)," which I conceived. This design allows the Attention mechanism to achieve "relative position encoding via an absolute position encoding method." Precisely because of this design, it is currently the only relative position encoding that can be used for Linear Attention.
RoFormer: https://github.com/ZhuiyiTechnology/roformer
Basic Idea
We briefly introduced RoPE in a previous article, "Transformer Position Encodings that Rack Researchers' Brains," where it was referred to as "fusion-style." This article provides a more detailed introduction to its origin and properties. In RoPE, our starting point is to "achieve relative position encoding through absolute position encoding." Doing so offers both theoretical elegance and practical utility; for instance, its ability to extend to Linear Attention is primarily due to this point.
To achieve this goal, we assume that absolute position information is added to $\boldsymbol{q}$ and $\boldsymbol{k}$ through the following operations:
\begin{equation}\tilde{\boldsymbol{q}}_m = \boldsymbol{f}(\boldsymbol{q}, m), \quad\tilde{\boldsymbol{k}}_n = \boldsymbol{f}(\boldsymbol{k}, n)\end{equation}
That is, we design operations $\boldsymbol{f}(\cdot, m)$ and $\boldsymbol{f}(\cdot, n)$ for $\boldsymbol{q}$ and $\boldsymbol{k}$ respectively, such that after these operations, $\tilde{\boldsymbol{q}}_m$ and $\tilde{\boldsymbol{k}}_n$ carry the absolute position information of $m$ and $n$. The core operation of Attention is the inner product, so we want the result of the inner product to carry relative position information. Therefore, we assume the existence of an identity relationship:
\begin{equation}\langle\boldsymbol{f}(\boldsymbol{q}, m), \boldsymbol{f}(\boldsymbol{k}, n)\rangle = g(\boldsymbol{q},\boldsymbol{k},m-n)\end{equation}
Thus, we need to solve for a (preferably simple) solution for this identity. The solving process also requires some initial conditions; clearly, we can reasonably set $\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}$ and $\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}$.
Solving Process
Following the same line of thought as the previous post, we first consider the two-dimensional case and solve it using complex numbers. In complex numbers, we have $\langle\boldsymbol{q},\boldsymbol{k}\rangle=\text{Re}[\boldsymbol{q}\boldsymbol{k}^*]$, where $\text{Re}[]$ represents the real part of the complex number, so we have:
\begin{equation}\text{Re}[\boldsymbol{f}(\boldsymbol{q}, m)\boldsymbol{f}^*(\boldsymbol{k}, n)] = g(\boldsymbol{q},\boldsymbol{k},m-n)\end{equation}
For simplicity, we assume there exists a complex number $\boldsymbol{g}(\boldsymbol{q},\boldsymbol{k},m-n)$ such that $\boldsymbol{f}(\boldsymbol{q}, m)\boldsymbol{f}^*(\boldsymbol{k}, n) = \boldsymbol{g}(\boldsymbol{q},\boldsymbol{k},m-n)$. Using the exponential form of complex numbers, we set:
\begin{equation}\begin{aligned}
\boldsymbol{f}(\boldsymbol{q}, m) =& R_f (\boldsymbol{q}, m)e^{\text{i}\Theta_f(\boldsymbol{q}, m)} \\
\boldsymbol{f}(\boldsymbol{k}, n) =& R_f (\boldsymbol{k}, n)e^{\text{i}\Theta_f(\boldsymbol{k}, n)} \\
\boldsymbol{g}(\boldsymbol{q}, \boldsymbol{k}, m-n) =& R_g (\boldsymbol{q}, \boldsymbol{k}, m-n)e^{\text{i}\Theta_g(\boldsymbol{q}, \boldsymbol{k}, m-n)} \\
\end{aligned}\end{equation}
Substituting these into the equation, we get the system of equations:
\begin{equation}\begin{aligned}
R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, n) =& R_g (\boldsymbol{q}, \boldsymbol{k}, m-n) \\
\Theta_f (\boldsymbol{q}, m) - \Theta_f (\boldsymbol{k}, n) =& \Theta_g (\boldsymbol{q}, \boldsymbol{k}, m-n)
\end{aligned}\end{equation}
For the first equation, setting $m=n$ gives:
\begin{equation}R_f (\boldsymbol{q}, m) R_f (\boldsymbol{k}, m) = R_g (\boldsymbol{q}, \boldsymbol{k}, 0) = R_f (\boldsymbol{q}, 0) R_f (\boldsymbol{k}, 0) = \Vert \boldsymbol{q}\Vert \Vert \boldsymbol{k}\Vert\end{equation}
The last equality stems from the initial conditions $\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}$ and $\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}$. Thus, we can simply set $R_f (\boldsymbol{q}, m)=\Vert \boldsymbol{q}\Vert$ and $R_f (\boldsymbol{k}, m)=\Vert \boldsymbol{k}\Vert$, meaning they do not depend on $m$. As for the second equation, setting $m=n$ similarly gives:
\begin{equation}\Theta_f (\boldsymbol{q}, m) - \Theta_f (\boldsymbol{k}, m) = \Theta_g (\boldsymbol{q}, \boldsymbol{k}, 0) = \Theta_f (\boldsymbol{q}, 0) - \Theta_f (\boldsymbol{k}, 0) = \Theta (\boldsymbol{q}) - \Theta (\boldsymbol{k})\end{equation}
Here $\Theta (\boldsymbol{q})$ and $\Theta (\boldsymbol{k})$ are the arguments (phases) of $\boldsymbol{q}$ and $\boldsymbol{k}$ themselves. The last equality again stems from the initial conditions. From the above, we obtain $\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q}) = \Theta_f (\boldsymbol{k}, m) - \Theta (\boldsymbol{k})$, meaning $\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q})$ must be a function related only to $m$ and independent of $\boldsymbol{q}$, denoted as $\varphi(m)$, such that $\Theta_f (\boldsymbol{q}, m) = \Theta (\boldsymbol{q}) + \varphi(m)$. Next, substituting $n=m-1$ and rearranging, we get:
\begin{equation}\varphi(m) - \varphi(m-1) = \Theta_g (\boldsymbol{q}, \boldsymbol{k}, 1) + \Theta (\boldsymbol{k}) - \Theta (\boldsymbol{q})\end{equation}
This implies that $\{\varphi(m)\}$ is an arithmetic progression. Let the right side be $\theta$, then we solve $\varphi(m)=m\theta$.
Encoding Form
In summary, for the 2D case using complex numbers, RoPE is expressed as:
\begin{equation}
\boldsymbol{f}(\boldsymbol{q}, m) = R_f (\boldsymbol{q}, m)e^{\text{i}\Theta_f(\boldsymbol{q}, m)}
= \Vert q\Vert e^{\text{i}(\Theta(\boldsymbol{q}) + m\theta)} = \boldsymbol{q} e^{\text{i}m\theta}\end{equation}
According to the geometric meaning of complex multiplication, this transformation corresponds to rotating the vector. Therefore, we call it "Rotary Position Embedding." It can also be written in matrix form:
\begin{equation}
\boldsymbol{f}(\boldsymbol{q}, m) =\begin{pmatrix}\cos m\theta & -\sin m\theta\\ \sin m\theta & \cos m\theta\end{pmatrix} \begin{pmatrix}q_0 \\ q_1\end{pmatrix}\end{equation}
Because the inner product satisfies linear additivity, any even-dimensional RoPE can be represented as a concatenation of 2D cases:
\begin{equation}\scriptsize{\underbrace{\begin{pmatrix}
\cos m\theta_0 & -\sin m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
\sin m\theta_0 & \cos m\theta_0 & 0 & 0 & \cdots & 0 & 0 \\
0 & 0 & \cos m\theta_1 & -\sin m\theta_1 & \cdots & 0 & 0 \\
0 & 0 & \sin m\theta_1 & \cos m\theta_1 & \cdots & 0 & 0 \\
\vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\
0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2-1} & -\sin m\theta_{d/2-1} \\
0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2-1} & \cos m\theta_{d/2-1} \\
\end{pmatrix}}_{\boldsymbol{\mathcal{R}}_m} \begin{pmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}\end{pmatrix}}\end{equation}
That is, multiplying vector $\boldsymbol{q}$ at position $m$ by matrix $\boldsymbol{\mathcal{R}}_m$ and vector $\boldsymbol{k}$ at position $n$ by matrix $\boldsymbol{\mathcal{R}}_n$, and performing Attention with the transformed sequences $\boldsymbol{Q}$ and $\boldsymbol{K}$, the Attention will automatically contain relative position information, because the following identity holds:
\begin{equation}(\boldsymbol{\mathcal{R}}_m \boldsymbol{q})^{\top}(\boldsymbol{\mathcal{R}}_n \boldsymbol{k}) = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_m^{\top}\boldsymbol{\mathcal{R}}_n \boldsymbol{k} = \boldsymbol{q}^{\top} \boldsymbol{\mathcal{R}}_{n-m} \boldsymbol{k}\end{equation}
Notably, $\boldsymbol{\mathcal{R}}_m$ is an orthogonal matrix; it does not change the magnitude of the vector, so it generally does not alter the stability of the original model.
Due to the sparsity of $\boldsymbol{\mathcal{R}}_m$, implementing it directly with matrix multiplication would waste computing power. It is recommended to implement RoPE in the following way:
\begin{equation}\begin{pmatrix}q_0 \\ q_1 \\ q_2 \\ q_3 \\ \vdots \\ q_{d-2} \\ q_{d-1}
\end{pmatrix}\otimes\begin{pmatrix}\cos m\theta_0 \\ \cos m\theta_0 \\ \cos m\theta_1 \\ \cos m\theta_1 \\ \vdots \\ \cos m\theta_{d/2-1} \\ \cos m\theta_{d/2-1}
\end{pmatrix} + \begin{pmatrix}-q_1 \\ q_0 \\ -q_3 \\ q_2 \\ \vdots \\ -q_{d-1} \\ q_{d-2}
\end{pmatrix}\otimes\begin{pmatrix}\sin m\theta_0 \\ \sin m\theta_0 \\ \sin m\theta_1 \\ \sin m\theta_1 \\ \vdots \\ \sin m\theta_{d/2-1} \\ \sin m\theta_{d/2-1}
\end{pmatrix}\end{equation}
where $\otimes$ denotes element-wise multiplication, i.e., the $*$ operation in frameworks like Numpy or Tensorflow. From this implementation, it is clear that RoPE can be viewed as a variant of multiplicative position encoding.
Long-Range Decay
As can be seen, RoPE is somewhat similar in form to Sinusoidal position encoding, except that Sinusoidal is additive, while RoPE can be considered multiplicative. In choosing $\theta_i$, we also followed the Sinusoidal scheme, i.e., $\theta_i = 10000^{-2i/d}$, which brings a certain degree of long-range decay.
The specific proof is as follows: after grouping $\boldsymbol{q}$ and $\boldsymbol{k}$ in pairs, the inner product with RoPE can be expressed via complex multiplication as:
\begin{equation}
(\boldsymbol{\mathcal{R}}_m \boldsymbol{q})^{\top}(\boldsymbol{\mathcal{R}}_n \boldsymbol{k}) = \text{Re}\left[\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i}\right]\end{equation}
Let $h_i = \boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^*$, $S_j = \sum\limits_{i=0}^{j-1} e^{\text{i}(m-n)\theta_i}$, and define $h_{d/2}=0, S_0=0$. By the Abel transformation (summation by parts), we get:
\begin{equation}\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i} = \sum_{i=0}^{d/2-1} h_i (S_{i+1} - S_i) = -\sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i)\end{equation}
Thus:
\begin{equation}\begin{aligned}
\left|\sum_{i=0}^{d/2-1}\boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^* e^{\text{i}(m-n)\theta_i}\right| \leq& \left|\sum_{i=0}^{d/2-1} S_{i+1}(h_{i+1} - h_i)\right| \\
\leq& \sum_{i=0}^{d/2-1} |S_{i+1}| |h_{i+1} - h_i| \\
\leq& \left(\max_i |h_{i+1} - h_i|\right)\sum_{i=0}^{d/2-1} |S_{i+1}|
\end{aligned}\end{equation}
Therefore, we can examine the behavior of $\frac{1}{d/2}\sum\limits_{i=1}^{d/2} |S_i|$ as relative distance changes as an indicator of decay property. The Mathematica code is as follows:
d = 128; \[Theta][t_] = 10000^(-2*t/d); f[m_] = Sum[ Norm[Sum[Exp[I*m*\[Theta][i]], {i, 0, j}]], {j, 0, d/2 - 1}]/(d/2); Plot[f[m], {m, 0, 256}, AxesLabel -> {Relative Distance, Relative Size}]
The result is shown in the figure below:
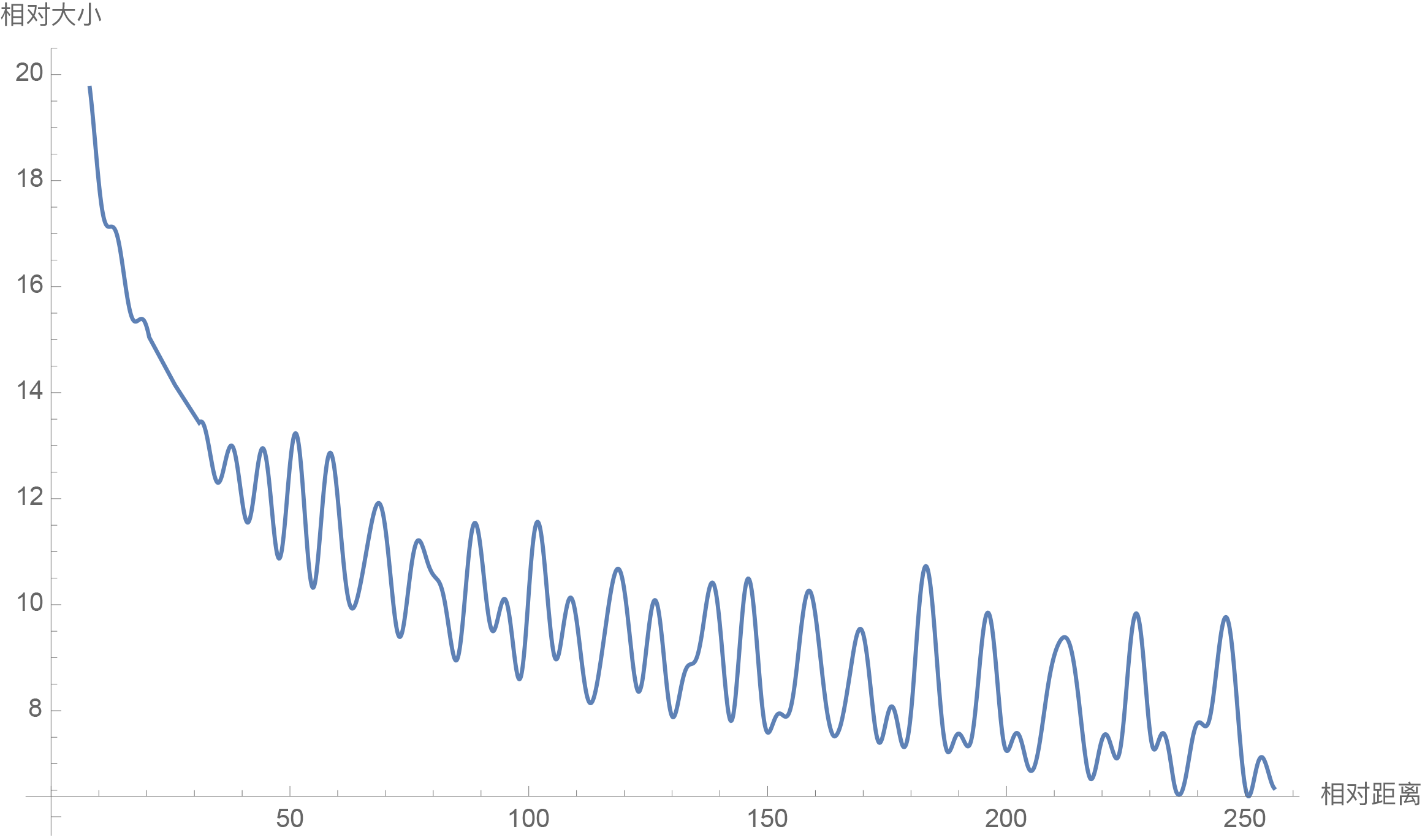
Long-range decay of RoPE (d=128)
From the graph, we can see that as the relative distance increases, the inner product result tends to decay. Therefore, choosing $\theta_i = 10000^{-2i/d}$ indeed brings some long-range decay. Of course, as mentioned in the previous article, this is not the only choice that can bring long-range decay; almost any smooth monotonic function would work. This choice was simply inherited from existing methods. I also tried initializing $\theta_i = 10000^{-2i/d}$ and treating $\theta_i$ as trainable parameters. After training for a while, I found that $\theta_i$ did not update significantly, so I simply fixed it to $\theta_i = 10000^{-2i/d}$.
Linear Scenarios
Finally, we point out that RoPE is currently the only relative position encoding that can be used for Linear Attention. This is because other relative position encodings are directly based on modifying the Attention matrix. However, Linear Attention does not compute the Attention matrix beforehand, so no such modification can be applied. For RoPE, it achieves relative position encoding through an absolute position encoding method, which does not require interacting with the Attention matrix, thus making its application to Linear Attention possible.
For an introduction to Linear Attention, we won't repeat it here. Interested readers can refer to "Exploring Linear Attention: Does Attention Need a Softmax?". A common form of Linear Attention is:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
where $\phi, \varphi$ are activation functions with non-negative output ranges. As seen, Linear Attention is also based on inner products, so a natural idea is to insert RoPE into the inner product:
\begin{equation}\frac{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]\boldsymbol{v}_j}{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]}\end{equation}
However, the problem is that the inner product $[\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]$ can be negative, so it is no longer a conventional probability attention, and there is a risk of the denominator being zero, which may bring instability during optimization. Considering that $\boldsymbol{\mathcal{R}}_i$ and $\boldsymbol{\mathcal{R}}_j$ are orthogonal matrices and do not change the length of the vectors, we can abandon the requirement for conventional probability normalization and use the following operation as a new type of Linear Attention:
\begin{equation}\frac{\sum\limits_{j=1}^n [\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
In other words, RoPE is only inserted in the numerator, while the denominator remains unchanged. Such attention is no longer probability-based (the attention matrix no longer satisfies non-negative normalization), but in a sense, it is still a normalization scheme, and there is no evidence that non-probabilistic attention is necessarily worse (for example, Nyströmformer also constructs attention without strictly following a probability distribution). Therefore, we tested it as a candidate, and our preliminary experimental results show that such Linear Attention is also effective.
Furthermore, in "Exploring Linear Attention: Does Attention Need a Softmax?" I also proposed another Linear Attention scheme: $\text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j) = 1 + \left( \frac{\boldsymbol{q}_i}{\Vert \boldsymbol{q}_i\Vert}\right)^{\top}\left(\frac{\boldsymbol{k}_j}{\Vert \boldsymbol{k}_j\Vert}\right)$. This does not depend on a non-negative range, and since RoPE does not change magnitudes, RoPE can be directly applied to this type of Linear Attention without changing its probabilistic significance.
Model Release
The first version of the RoFormer model has been completed and open-sourced on GitHub:
RoFormer: https://github.com/ZhuiyiTechnology/roformer
Simply put, RoFormer is a WoBERT model where absolute position encoding is replaced by RoPE. The structural comparison with other models is as follows:
\begin{array}{c|cccc}
\hline
& \text{BERT} & \text{WoBERT} & \text{NEZHA} & \text{RoFormer} \\
\hline
\text{Token unit} & \text{Character} & \text{Word} & \text{Character} & \text{Word} \\
\text{Pos Encoding} & \text{Absolute} & \text{Absolute} & \text{Classic Relative} & \text{RoPE}\\
\hline
\end{array}
During pre-training, based on WoBERT Plus, we adopted a mixed training method with multiple sequence lengths and batch sizes to allow the model to adapt to different training scenarios in advance:
\begin{array}{c|ccccc}
\hline
& \text{maxlen} & \text{batch size} & \text{steps} & \text{final loss} & \text{final acc}\\
\hline
1 & 512 & 256 & 20\text{w} & 1.73 & 65.0\%\\
2 & 1536 & 256 & 1.25\text{w} & 1.61 & 66.8\%\\
3 & 256 & 256 & 12\text{w} & 1.75 & 64.6\%\\
4 & 128 & 512 & 8\text{w} & 1.83 & 63.4\%\\
5 & 1536 & 256 & 1\text{w} & 1.58 & 67.4\%\\
6 & 512 & 512 & 3\text{w} & 1.66 & 66.2\%\\
\hline
\end{array}
As seen from the table, as sequence length increases, the pre-training accuracy actually improves. This partially reflects RoFormer's processing effect on long-text semantics and demonstrates RoPE's good extrapolation capability. On short-text tasks, RoFormer performs similarly to WoBERT; RoFormer's main feature is that it can directly handle sequences of arbitrary length. Below are our experimental results on the CAIL2019-SCM task:
\begin{array}{c|cc}
\hline
& \text{Validation} & \text{Test} \\
\hline
\text{BERT-512} & 64.13\% & 67.77\% \\
\text{WoBERT-512} & 64.07\% & 68.10\% \\
\text{RoFormer-512} & 64.13\% & 68.29\% \\
\text{RoFormer-1024} & \textbf{66.07%} & \textbf{69.79%} \\
\hline
\end{array}
The parameter after the hyphen denotes the maxlen during fine-tuning. It can be seen that RoFormer indeed handles long-text semantics significantly better. As for hardware requirements, running maxlen=1024 on a 24G memory card allows for a batch_size of 8 or more. Currently, this is the only Chinese task I've found suitable for testing long-text capabilities, so long-text testing was limited to this. Readers are welcome to test it or suggest other evaluation tasks.
Of course, though RoFormer can theoretically handle arbitrary-length sequences, it currently still has quadratic complexity. We are currently training a RoFormer model based on Linear Attention and will open-source it upon completion of experiments. Please stay tuned.
(Note: RoPE and RoFormer have been organized into a paper "RoFormer: Enhanced Transformer with Rotary Position Embedding" submitted to Arxiv. Feel free to use and cite! Haha~)
Summary
This article introduced our self-developed Rotary Position Embedding (RoPE) and the corresponding pre-trained model RoFormer. Theoretically, RoPE shares some commonalities with Sinusoidal position encoding, but it does not rely on Taylor expansion and is more rigorous and interpretable. From the results of the RoFormer pre-trained model, RoPE possesses good extrapolation properties, and its application in Transformers demonstrates strong long-text processing capabilities. Additionally, RoPE is currently the only relative position encoding applicable to Linear Attention.